
로딩 중이에요... 🐣
[코담]
웹개발·실전 프로젝트·AI까지, 파이썬·장고의 모든것을 담아낸 강의와 개발 노트
01 Pandas설치 | ✅ 저자: 이유정(박사)
https://pandas.pydata.org/docs/getting_started/install.html
Pandas란 무엇인가? Pandas는 Python에서 데이터 분석과 처리를 매우 쉽게 할 수 있게 해주는 라이브러리(도구)입니다. 엑셀처럼 표 형태의 데이터를 다루는 데 강력한 기능을 제공합니다.
Pandas로 할 수 있는 일은?
| 작업 | 설명 |
|---|---|
| CSV, Excel 불러오기 | pd.read_csv(), pd.read_excel() |
| 데이터 정리 | 결측치 처리, 열 추가, 삭제, 필터링 |
| 그룹 분석 | groupby()로 통계 집계 |
| 정렬/정규화 | 날짜 정렬, 숫자 기준 정렬 |
| 시계열 데이터 처리 | 시간 데이터 다루기 |
| 파일 저장 | CSV, Excel 등으로 다시 저장 가능 |
Pandas를 많이 사용하는 분야는?
- 데이터 분석 (Data Analysis)
- 머신러닝 전처리 (Data Preprocessing)
- 금융 데이터 분석
- 웹 크롤링 후 데이터 정리
- BI(비즈니스 인텔리전스)
크롤링한 데이터를 바로 DataFrame으로 사용하여 파일을 저장하지 않고도 바로 Pandas로 처리가 가능합니다.
import pandas as pd
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
res = requests.get(url)
soup = BeautifulSoup(res.text, "html.parser")
# 예시: ul > li 안의 텍스트 수집
items = [li.text for li in soup.select("li")]
# 바로 DataFrame으로 변환
df = pd.DataFrame(items, columns=["내용"])
print(df.head())
그리고 CSV로 저장도 가능합니다.
df.to_csv("결과파일.csv", index=False)
설치
pip install pandas
쥬피터 노트북 실행
jupyter notebook --no-browser --port=8888
쥬피터 노트북에서 저장된 csv파일 불러오기:
import pandas as pd
df = pd.read_csv("csv_files/combined_customers.csv")
df.groupby("age")["customer_id"].count().reset_index(name="customer_count")
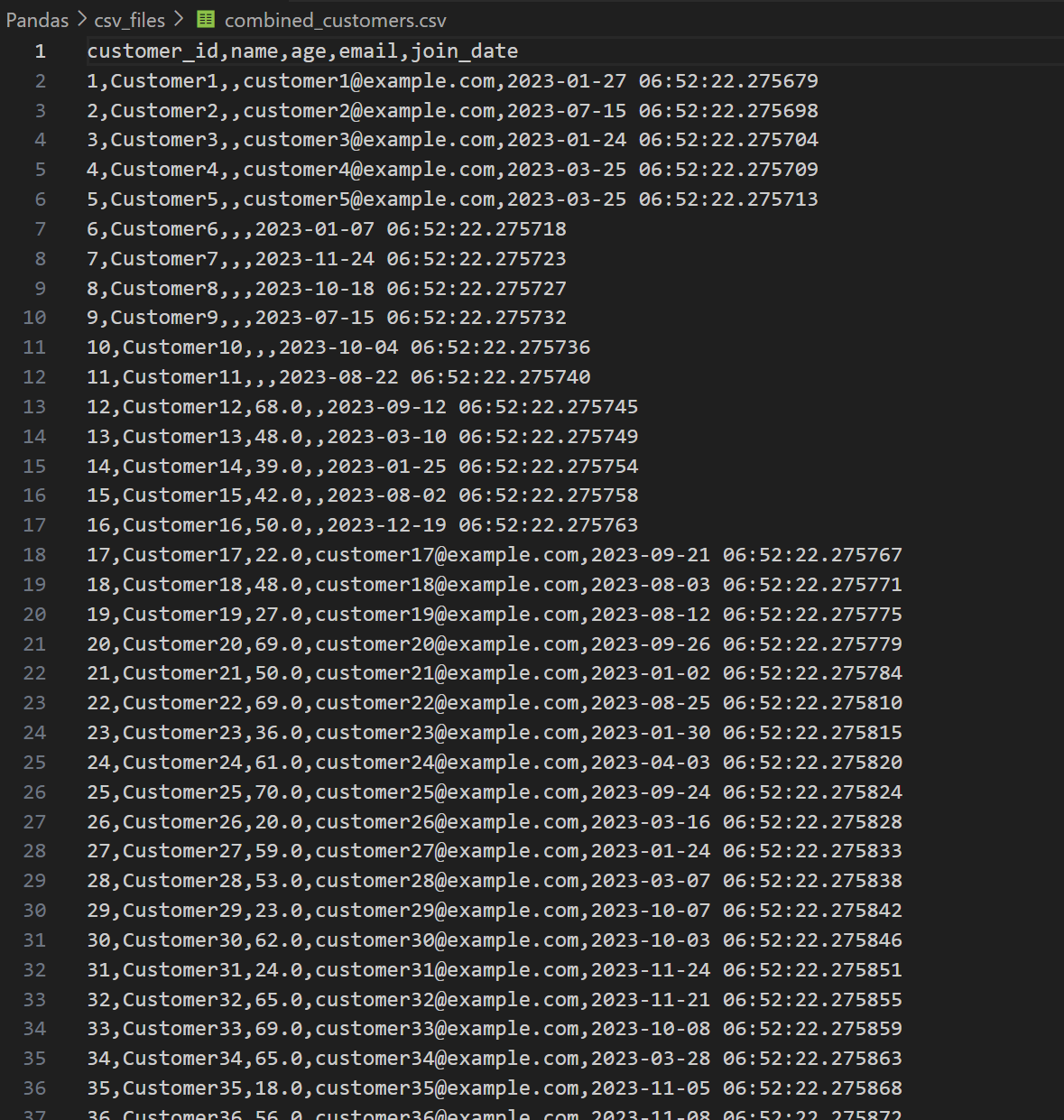 데이터에는 customer_id, name, age, email, join_date 이렇게 있습니다.
데이터에는 customer_id, name, age, email, join_date 이렇게 있습니다.
df = pd.read_csv("csv_files/combined_customers.csv")
combined_customers.csv라는 CSV 파일을 읽어서df라는 변수에 저장합니다.df는 DataFrame 객체로, 엑셀처럼 생긴 표 구조예요.
df.groupby("age")
age(나이) 컬럼을 기준으로 데이터를 그룹화합니다. 같은 나이끼리 묶어요.- 즉, 같은 나이끼리 묶습니다 (예: 22살인 사람들끼리 한 그룹).
["customer_id"]
- 각 나이 그룹마다
customer_id가 비어 있지 않은 행의 수를 셉니다. - 즉, 그 나이에 속한 고객이 몇 명인지 계산합니다.
- 단,
age가NaN(비어있는 값)인 행은 자동으로 제외됩니다!
.count()
- 각 나이 그룹에 해당하는
customer_id의 개수를 셉니다. 즉, 고객 수를 셉니다.
.reset_index(name="customer_count")
groupby결과는 인덱스가age인 상태이므로,- 이를 일반 열로 바꾸고, 세어준 값의 열 이름을
"customer_count"로 지정합니다.
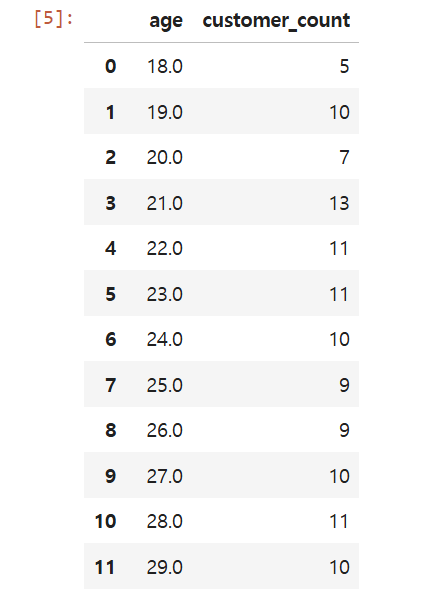
결과는:
18살 그룹은 5명
19살 그룹은 10명
.....
df.groupby("age")["customer_id"].count()
즉 나이끼리 그룹을 묶고 같은 나이끼리 id의 숫자를 세어 나온 합계입니다.
빠진 값(NaN)은 어떻게 처리됐을까?
groupby()는NaN값을 그룹으로 사용하지 않습니다.count()는 기본적으로NaN은 세지 않습니다.
빠르게 데이터 구조 확인할 때 사용
df.head() # 데이터의 처음 5줄을 보여줌
끝부분 데이터 확인할 때 사용
df.tail() # 데이터의 마지막 5줄을 보여줌
데이터 분포 파악용
df.describe()
# 수치형 열의 기초 통계량 제공(평균,표준편차,최대/최소값 등)
범주형 데이터의 빈도 확인
df["age"].value_counts() # 각 값이 몇 번 나왔는지 세기