
로딩 중이에요... 🐣
21 melt와 pivot을 이용한 데이터 재구성 | ✅ 저자: 이유정(박사)
melt와 pivot

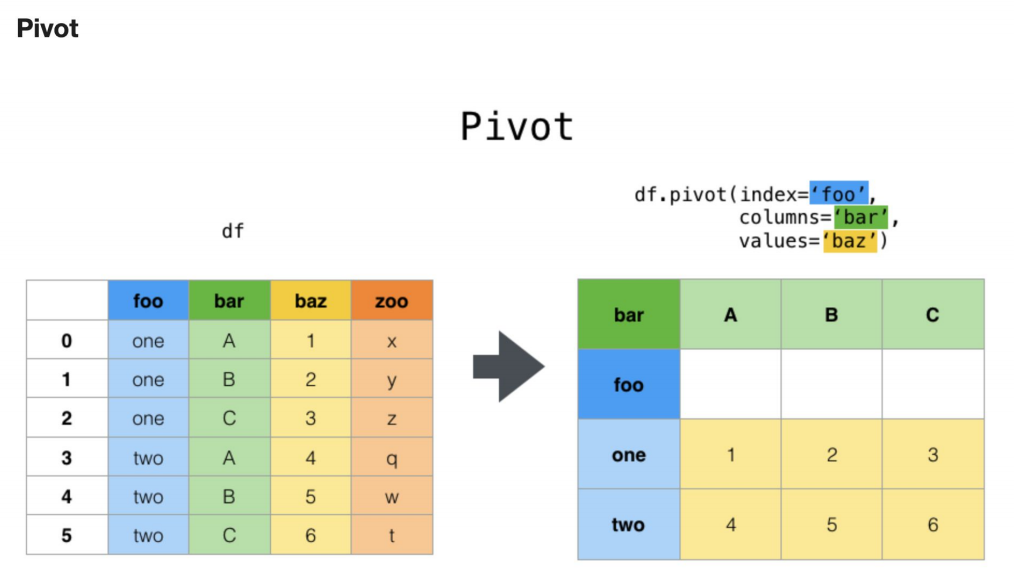
pivot() 함수란?
엑셀에서 피벗 테이블을 만든다고 생각하면 됩니다.
- 세로로 되어 있는 데이터를
- 가로로 펼쳐서 표처럼 보기 좋게 만드는 것이에요.
- 행과 열의 구조를 바꿔서 가독성과 분석 효율을 높이는 것이 목적 입니다.
zoo까지 확장해서 그리면:

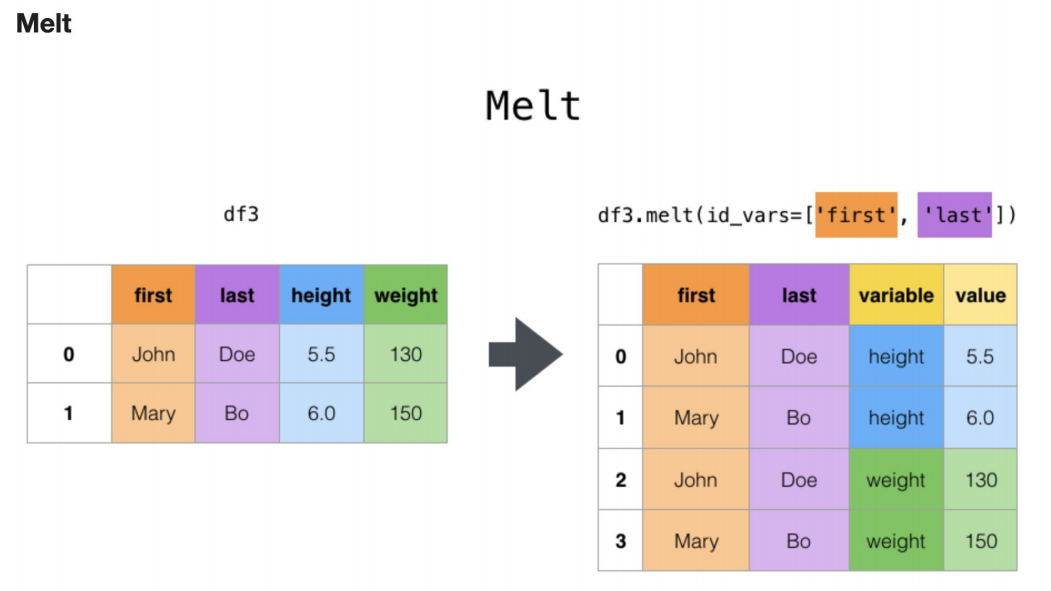
melt 함수란?
표 형태의 데이터를 "세로로 길게 펼쳐서" 정리해주는 함수예요.
하나의 열(column)에 들어 있던 여러 값을, 여러 행(row) 으로 바꿔주는 기능입니다.
쉽게 말해…
넓은(wide) 형태 → → → 긴(long) 형태로 바꿈
즉, 한 줄에 여러 정보가 있던 것을
한 줄에 하나의 정보만 있도록 바꾸는 것!
데이터 재구성의 중요성 melt와 pivot을 이용한 데이터 재구성
데이터 재구성이 왜 중요할까?
우리가 수집한 원본 데이터(Raw 데이터)는 대부분 있는 그대로 저장된 형태입니다. 이런 데이터는 컴퓨터 입장에서는 문제가 없지만, 사람이 보기에는 너무 복잡하거나, 중복이 많거나, 분석하기 어렵게 되어 있는 경우가 많습니다.
예를 들어, 한 행에 여러 정보가 들어 있어서 눈으로 비교하거나
차트로 그리기 어려운 형태일 수 있죠.
import pandas as pd
df = pd.read_csv("csv_files/melt_pivot_data.csv")
# pivot 함수 사용 예시
pivoted_df = df.pivot(index='day', columns='measurement', values='value')
# 결과 확인
print(pivoted_df)
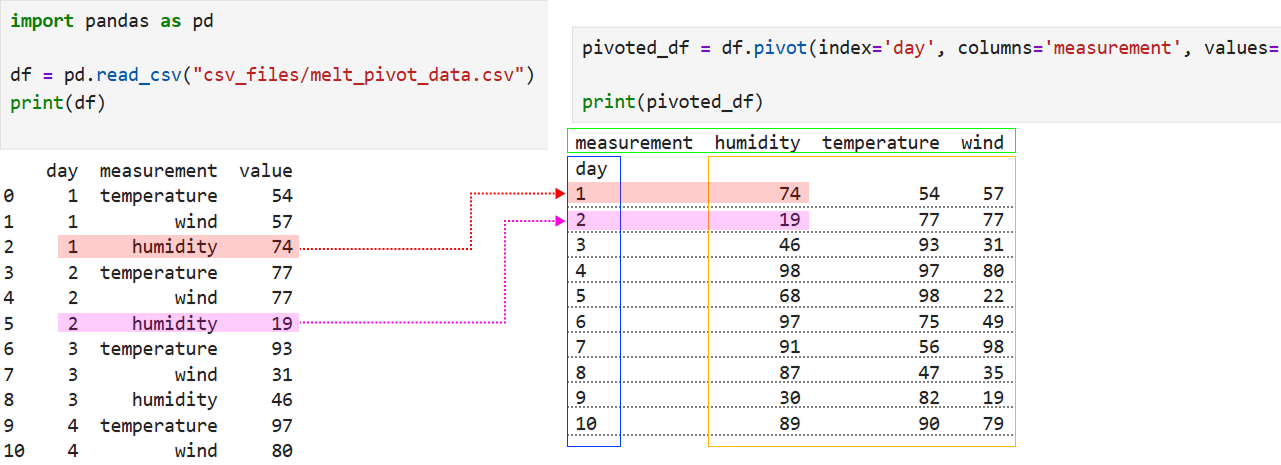
index='day'
- 행 인덱스로 사용할 열입니다.
- 결과에서 각
day값이 행의 인덱스(index)가 됩니다. - 이 열은 축(행 방향)으로 유지됩니다.
columns='measurement'
- 열(컬럼) 이름으로 사용할 값입니다.
- 이 열의 고유 값들(
temp,humidity)이 새로운 열 이름이 됩니다.
values='value'
- 각 셀에 들어갈 값.
- 예를 들어
(day=1, measurement='temp')→value=22.0
pivot한 테이블을 다시 원상복구시키기 위해 melt함
import pandas as pd
# CSV 파일 불러오기
df = pd.read_csv("csv_files/melt_pivot_data.csv")
print(df)
# pivot: 측정값(measurement)을 열(columns)로, 날짜(day)를 인덱스로, 값(value)을 셀 값으로 설정
# 긴 형태의 데이터를 넓은 형태(wide format)로 변환
pivoted_df = df.pivot(index='day', columns='measurement', values='value')
print(pivoted_df)
# melt: 피벗된 넓은 데이터를 다시 긴 형태(long format)로 되돌림
# day는 식별자로 유지(id_vars), 나머지 열을 녹여서 measurement와 value 컬럼으로 생성
melted_df = pivoted_df.reset_index().melt(id_vars=['day'], var_name='measurement', value_name='value')
print(melted_df)
# 만약 원본 순서대로 인덱스를 해야 한다면
df['original_order'] = range(len(df))
melted_df_sorted = pd.merge(melted_df, df, on=['day', 'measurement', 'value'])
melted_df_sorted = melted_df_sorted.sort_values('original_order').drop(columns='original_order')
# 결과확인
print(melted_df_sorted)
pivot → melt(원상복귀)하는 주요 이유
-
데이터 가공 후 원래 구조로 되돌리기 위해
- 피벗된 상태에서 계산(예: 평균, 차이, 비율 등)을 수행한 후
다시 분석/저장/시각화를 위해 긴 형식으로 복원합니다.
- 피벗된 상태에서 계산(예: 평균, 차이, 비율 등)을 수행한 후
-
사람이 보기 좋게 표 형태로 정리했다가, 다시 프로그램이 쓰기 쉽게 돌리기 위해
pivot()은 가독성을 높이고,
melt()는 머신러닝, 시각화, 그룹 분석 등에 적합한 구조로 변환합니다.
-
측정 항목(measurement) 순서를 정렬하거나 구조를 통일시키기 위해
pivot()시 열(column)이 자동 정렬되기 때문에
melt()후에도 같은 항목끼리 모인 형태가 됩니다.
-
데이터 저장 또는 재사용을 위해
- 넓은 형태보다 긴 형태가 CSV, DB 등 다양한 포맷에 더 적합합니다.
-
시각화 라이브러리에서 요구하는 형식으로 바꾸기 위해
- 예:
seaborn,plotly,altair등은 긴 형식을 선호합니다.
- 예:
-
그룹별 연산(groupby)이나 조건 필터링을 쉽게 하기 위해
- 긴 형식이 있어야
groupby('measurement')같은 연산이 자연스럽게 됩니다.
- 긴 형식이 있어야
pivot → melt로 원상복귀시켰더니, 원래 순서가 아닌 정렬된 상태로 바뀐것은 melt과정에서 열순서를 그대로 따라갔기 때문입니다.