
로딩 중이에요... 🐣
01 무신사 웹 크롤링 | ✅ 저자: 이유정(박사)
API호출방식
https://www.crummy.com/software/BeautifulSoup/bs4/doc.ko/
라이브러리 설치
mkdir musinsa-bot
cd musinsa-bot
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install requests beautifulsoup4 discord.py python-dotenv
pip list
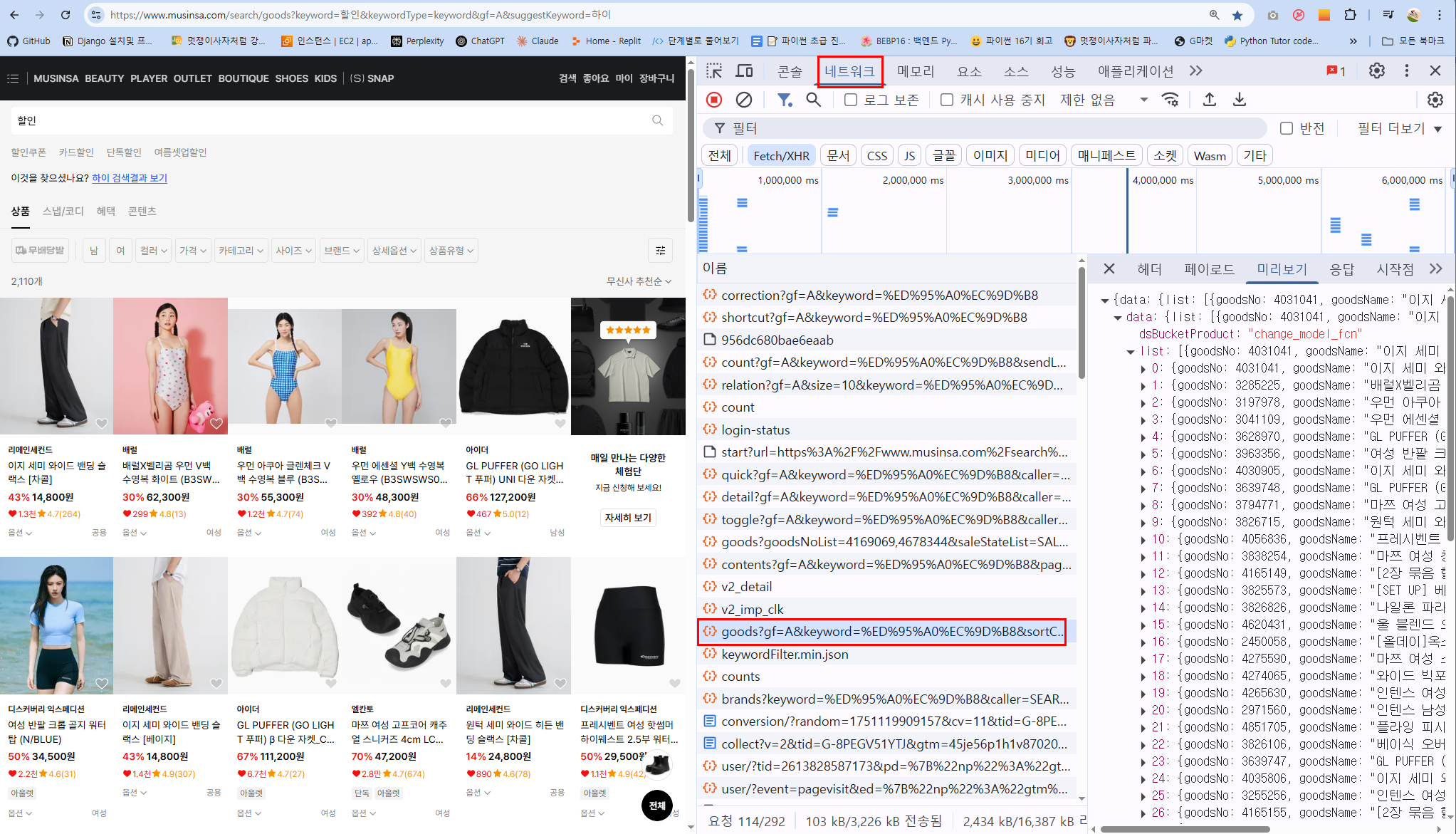
무신사 할인 페이지주소 https://www.musinsa.com/search/goods?keyword=%ED%95%A0%EC%9D%B8&gf=A&suggestKeyword=%ED%95%98%EC%9D%B4
- F12에서 개발자 도구열기
- 상단탭중 Network(네트워크)클릭 (이때 새로고침을 해야 API요청들이 보입니다.)
- 필터링:
XHR또는Fetch탭 선택 이건 JavaScript 기반 비동기 요청만 보여주는 필터입니다.
HTML은 제외하고 API만 볼 수 있어서 매우 유용합니다. - 검색창에
recommend입력 : 아래와 같이 생긴 URL이 보일 것입니다
https://api.musinsa.com/api2/hm/web/v4/pans/recommend?storeCode=musinsa&gf=A&page=2&size=10&index=16&scenarioIndex=8
쿼리스트링 파라미터 분리: 위의 주소를 분리합니다:
class MusinsaAPI:
def __init__(self):
self.url = "https://api.musinsa.com/api2/hm/web/v4/pans/recommend"
self.params = {
"storeCode":"musinsa",
"gf":"A",
"page":2,
"size":10,
"index":16,
"scenarioIndex":8,
}
✅ 파라미터 추출 코드
from urllib.parse import urlparse, parse_qs
import pprint
def extract_params(url: str):
parsed_url = urlparse(url)
query_dict = parse_qs(parsed_url.query)
# parse_qs는 value를 리스트로 반환하므로, 첫 번째 값만 추출
simplified = {k: v[0] for k, v in query_dict.items()}
print("params = {")
for key, value in simplified.items():
print(f' "{key}": "{value}",')
print("}")
# 예시 URL
url = "https://api.musinsa.com/api2/dp/v1/plp/goods?gf=A&keyword=할인&sortCode=POPULAR&page=1&size=60&caller=SEARCH"
extract_params(url)
🖨️ 결과
params = {
"gf": "A",
"keyword": "할인",
"sortCode": "POPULAR",
"page": "1",
"size": "60",
"caller": "SEARCH",
}
상품주소
https://api.musinsa.com/api2/dp/v1/plp/goods?
gf=A&
keyword=%ED%95%A0%EC%9D%B8&
sortCode=POPULAR&
page=1&
size=60&
caller=SEARCH
쿼리스트링 파라미터 분리
네트워크 탭에서 본 ?key=value&key2=value2… 부분을
params = {
"gf": "A",
"keyword": "할인",
"sortCode": "POPULAR",
"page": 1,
"size": 60,
"caller": "SEARCH",
}
처럼 Python 딕셔너리로 옮겨 적습니다.
requests.get(self.url, params=params, headers=headers) 하면 자동 인코딩(%ED%95%A0→할인)도 처리해 줍니다.
개발자 도구에서 콘솔에 navigator.userAgent 입력하여 값을 얻어낸다.
self.headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36",
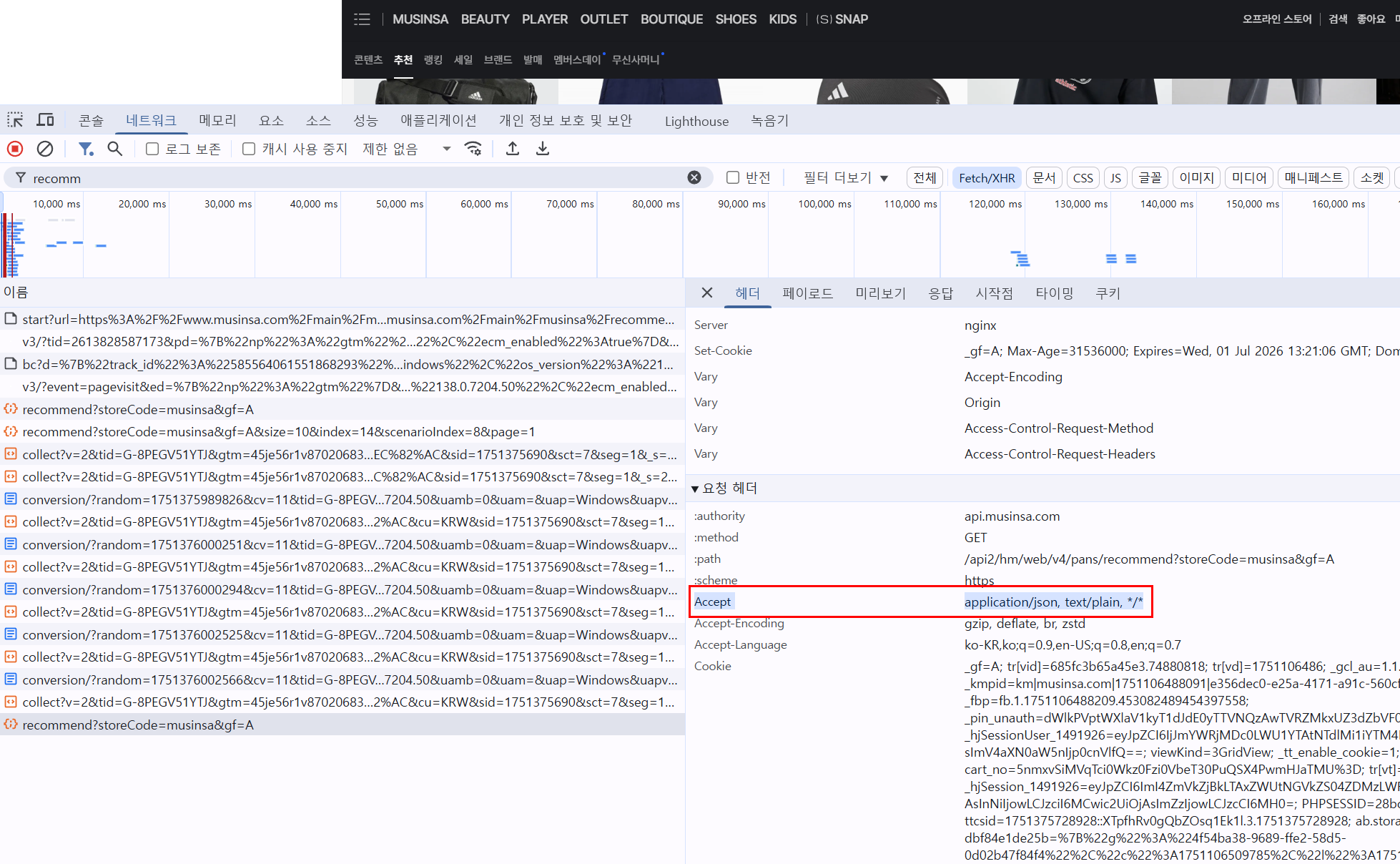
- 상단 탭에서 "Network(네트워크)" 선택
- 상품 리스트가 나오는 API 요청을 클릭 (예:
/recommend,/goods, 등) - 오른쪽 패널에서 Headers 탭 → Request Headers 항목 확인
- 거기에 이런 부분이 나옵니다:
Request Headers:
Accept: application/json, text/plain, */*
이부분을 입력합니다.
"Accept":"application/json, text/plain, */*",
}
Accept 헤더가 하는 역할
Accept 헤더는 서버에 어떤 타입의 응답을 받고 싶은지를 알려주는 정보입니다.
application/json : JSON 형태로 응답을 받고 싶다는 뜻
text/plain : 일반 텍스트도 허용
*/* : 어떤 타입이든 상관없음 (fallback)
뽑고 싶은 정보
- 배너 이미지 URL →
item["image"]["url"] - 배너 제목 →
item["info"]["title"]["text"] - 서브 제목 →
item["info"]["subTitle"]["text"] - 클릭 시 이동 URL →
item["url"]
HTML을 파싱하지 않고, 브라우저가 내부에서 쓰는 JSON API를 직접 호출하는 방법입니다.
- 사이트 주소(API 엔드포인트) 찾기
- 브라우저에서 F12 → Network 탭 → XHR/Fetch 필터 켜기
- Musinsa 검색·타임세일 페이지(또는 원하는 페이지)를 새로고침
- 리스트를 불러오는 요청(
goods?...또는/api2/dp/v1/plp/goods등)이 뜨면- Name 열에 나타나는 항목이 API 엔드포인트 URL
- 클릭 후 오른쪽 Response 에 JSON이 보이면 바로 그 URL이 맞습니다
scraper.py 코드작성 : requests 로 API 호출 및 JSON 파싱
import requests
from typing import List, Dict
import requests
- requests는 파이썬에서 HTTP 요청(웹 페이지나 API에 데이터를 가져오거나 보낼 때 쓰는 통신 방식)을 아주 간단한 문법으로 다룰 수 있게 해 주는 외부 라이브러리입니다.
- 예를 들어 requests.get(url) 하면 그 URL에 GET 요청을 보내고 응답을 받을 수 있어요.
from typing import List, Dict
- 이 두 개는 타입 힌트(type hints) 에 쓰이는 클래스입니다.
List[Dict]같은 표현을 통해 “이 함수는 딕셔너리(Dict)를 담은 리스트(List)를 반환합니다”라고 코드를 문서화(documentation) 하는 역할을 합니다.
class MusinsaAPI():
"""
Musinsa 상품 정보를 크롤링하는 API 클래스.
keyword, page, size 파라미터로 검색어, 페이지, 개수를
동적으로 설정할 수 있습니다.
"""
class MusinsaAPI:
- MusinsaAPI라는 새로운 타입(클래스) 을 정의합니다.
- 이 클래스를 사용하면 “무신사 API에 접속해서 상품 데이터를 가져오는” 기능을 한 덩어리(객체) 로 묶어서 편하게 쓸 수 있어요.
def __init__(self, keyword: str = "할인", page: int = 1, size: int = 60):
def __init__(…)
- 클래스의 생성자(constructor) 로,
MusinsaAPI(...)로 객체를 만들 때 자동으로 실행되는 코드 블록입니다. - keyword, page, size라는 세 개의 매개변수를 받으며, 각각 검색어, 페이지 번호, 한 페이지에 몇 개를 가져올지 정합니다.
keyword: str = "할인"과 같은 표기를 타입 힌트라고 하고, = "할인" 부분은 “기본값”을 지정한 겁니다.MusinsaAPI()처럼 아무 인자를 안 주면 keyword가 “할인”으로 자동 설정됩니다.
# API 엔드포인트
self.url = "https://api.musinsa.com/api2/dp/v1/plp/goods"
# 요청 파라미터 설정
self.params = {
"gf": "A",
"keyword": keyword,
"sortCode": "POPULAR",
"page": page,
"size": size,
"caller": "SEARCH",
}
# 요청 헤더 설정
self.headers = {
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/138.0.0.0 Safari/537.36"
),
"Accept": "application/json, text/plain, */*",
}
self.url
- 무신사 API의 접속 주소(URL) 입니다.
- 나중에 requests.get(self.url, ...) 할 때 사용합니다.
self.params
- GET 요청에 함께 붙여 보낼 파라미터들을 딕셔너리로 모아 둔 것
- 예: keyword가 “신발”이면 ?keyword=신발 이라는 쿼리스트링이 URL 뒤에 자동으로 붙어요.
self.headers
- HTTP 요청 시 헤더(Header) 에 들어갈 정보입니다.
- 보통 User-Agent를 지정해야 API가 “정상적인 브라우저에서 보낸 요청”으로 인식하기 때문에 브라우저처럼 가장한 문자열을 넣습니다.
def fetch(self) -> List[Dict]:
"""
Musinsa API를 호출하여 상품 리스트를 반환합니다.
Returns:
List[Dict]: 상품 정보 딕셔너리의 리스트
"""
# GET 요청 수행
response = requests.get(self.url, params=self.params, headers=self.headers)
response.raise_for_status()
data = response.json()
def fetch(self) -> List[Dict]:
- fetch 메서드는 “가져온다”라는 뜻으로, 실제로 HTTP 요청을 보내고 API 응답을 파싱(parsed) 해서 파이썬 객체(리스트/딕셔너리)로 돌려줍니다.
– ->
List[Dict]은 “반환값이 딕셔너리의 리스트(List of Dict)입니다”라는 타입 힌트입니다.
requests.get(...)
self.url에 GET 요청을 보내고,params=self.params를 통해 쿼리파라미터를 붙이고,headers=self.headers를 통해 헤더를 설정합니다.
response.raise_for_status()
- HTTP 상태코드가 200번대가 아니면 여기서 예외(에러) 를 터뜨립니다.
- 만약 404, 500 같은 에러가 내려오면 이후 코드를 실행하지 않고 에러 내용을 보여줘서 “왜 실패했나”를 알 수 있어요.
response.json()
- 응답 본문(Body)을 JSON → 파이썬 딕셔너리(dict)로 자동 변환 해 줍니다.
goods_list = data.get("data", {}).get("list", [])
if not goods_list:
return []
data 안쪽 구조를 보면 보통:
{
"data": {
"list": [ /* 상품 배열 */ ]
}
}
.get("data", {}) 처럼 쓰면, 만약 "data" 키가 없다면 빈 딕셔너리를 대신 꺼내 주고,
.get("list", []) 는 "list"가 없으면 빈 리스트를 꺼내 줍니다.
if not goods_list: 는 “상품 리스트가 비어 있으면 그냥 빈 리스트를 돌려줘!” 라는 뜻입니다.
result: List[Dict] = []
for g in goods_list:
result.append({
"goodsNo": g.get("goodsNo"),
"name": g.get("goodsName", ""),
"brand": g.get("brandName", ""),
"originalPrice": f"{g.get('originalPrice', 0)}원",
"salePrice": f"{g.get('price', 0)}원",
"url": "https://www.musinsa.com" + g.get("goodsUrl", ""),
"image": g.get("imageUrl", ""),
})
return result
result: List[Dict] = []
- 빈 리스트를 하나 만듭니다.
- 앞으로 이 안에 파이썬 딕셔너리(상품 정보) 를 하나씩 채워 넣을 거예요.
for g in goods_list:
- goods_list 에 들어 있는 상품 하나하나(g)를 순서대로 꺼내서 반복합니다.
result.append({...})
- g(원본 데이터)에서 필요한 값들만 추려서 새로운 딕셔너리
({ "name": ..., "salePrice": ... })를 만들고 result 리스트에 하나씩 추가합니다.
f"{g.get('price', 0)}원"
- Python의 f-string 문법으로, 중괄호 안에 변수·표현식을 쓰면 문자열 안에 변수값을 바로 끼워 넣을 수 있습니다.
- 예:
price = 29300이면f"{price}원"은"29300원"이 돼요.
return result
- 반복이 끝나면, 완성된 result 리스트를 호출한 쪽(다른 코드)으로 되돌려 줍니다.
if __name__ == "__main__":
# 예시 실행: 신발 키워드로 상위 5개 상품 출력
api = MusinsaAPI(keyword="신발", size=5)
items = api.fetch()
for idx, item in enumerate(items, start=1):
print(f"{idx}. {item['name']} - {item['salePrice']} ({item['url']})")
if __name__ == "__main__":
직접 실행 (python scraper.py):
이 경우 파이썬은 그 파일을 “메인 스크립트”로 보고 __name__ 에 "__main__" 을 넣습니다.
그래서 if __name__ == "__main__": 블록 안의 코드를 실행하게 되며,
다른 곳에서 import (from scraper import MusinsaAPI):
이 땐 파이썬이 모듈 이름 그대로인 "scraper" 를 __name__에 넣습니다.
즉,
테스트나 예제 실행이 필요할 때는 python scraper.py 로 바로 돌리고,
다른 코드에서 기능만 재사용할 땐 import scraper 만 하면,
내부 테스트 코드는 전혀 실수로 실행되지 않아 안전하게 쓸 수 있습니다.
객체생성
api = MusinsaAPI(keyword="신발", size=5)
MusinsaAPI(...)클래스는__init__()메서드가 실행되어 새로운 인스턴스(객체) 가 만들어집니다.괄호()안에keyword="신발"은 “검색어를 ‘신발’로 설정” 하라는 의미입니다.size=5은 한 번에 5개만 가져오라는 뜻이고,page는 생략했으므로 자동으로 기본값1이 적용됩니다.
__init__ 메서드에 매개변수들
class MusinsaAPI:
def __init__(self, keyword: str = "할인", page: int = 1, size: int = 60):
우리가 넘긴 인자들:
MusinsaAPI(keyword="신발", size=5)
생성자(__init__)의 keyword 매개변수에 "신발" 이라는 값을 넣어 달라는 의미
생성자의 size 매개변수에 5 라는 값을 넣어 달라는 의미
그러면 내부에서는
def __init__(self, keyword, page, size):
self.params = {
"keyword": keyword, # 여기에 "신발"이 들어가고,
"page": page, # 여기에 1 (기본값)이 들어가고,
"size": size # 여기에 5가 들어갑니다.
}
# 나머지 API 호출 준비 작업…
self.params["keyword"]에"신발"이 저장self.params["page"]에1(기본값)self.params["size"]에5
api.params의 결과는
{
"keyword": "신발",
"page": 1,
"size": 5,
…
}
items = api.fetch()
fetch()메서드는 HTTP 요청을 보내서 무신사 API에서 상품 데이터를 가져오는 기능을 담당합니다- 내부적으로
requests.get(self.url, params=self.params, headers=self.headers)를 실행해 데이터를 받아오고, 받아온 JSON 응답을 파이썬 리스트/딕셔너리로 파싱(parse) 한 다음, 우리가 쓸 수 있게 필요한 필드(name, price, url 등) 만 모아서 리스트 형태로 묶어서 돌려주는(return) 메서드입니다.
구체적인 처리흐름:
def fetch(self) -> List[Dict]:
# 1) API 서버에 GET 요청 보내기
response = requests.get(self.url, params=self.params, headers=self.headers)
# 2) 상태 코드가 200번대가 아니면 에러로 처리
response.raise_for_status()
# 3) JSON 응답을 파이썬 객체(dict)로 변환
data = response.json()
# 4) 실제 상품 리스트 부분(data["data"]["list"])을 꺼내기
goods_list = data.get("data", {}).get("list", [])
# 5) 각 상품에서 필요한 값(name,salePrice...)만 골라 새 dict로 만들기
result = []
for g in goods_list:
result.append({
"name": g.get("goodsName", ""),
"salePrice": f"{g.get('price', 0)}원",
"url": "https://www.musinsa.com" + g.get("goodsUrl", ""),
# … 그 외 필드 …
})
# 6) 완성된 리스트 반환
return result
⏭️ 응용 팁:
- Discord 봇과 연결할 땐:
items = MusinsaAPI(keyword="반팔", size=5).fetch()
for i in items:
await message.channel.send(i["name"])
처럼, fetch() 결과를 디스코드 채팅으로 보내 줄 수 있습니다.
검색어(keyword), 페이지(page), 개수(size) 를 on_message 내부에서 동적으로 바꿔 주면 사용자 메시지에 따라 “신발”, “반팔”, “3만원 이하” 등
다양한 필터링이 가능합니다.
requests 말고도 httpx 같은 다른 HTTP 라이브러리도 있습니다. 하지만 requests가 가장 배우기 쉽고 자료가 많이 있습니다.
이렇게 클래스와 메서드를 단계별로 나눠 보면,
- 생성자(init): API 호출에 필요한 설정을 저장
- fetch(): 실제로 HTTP 요청을 보내고 JSON을 파싱→정리
__main__블록: “단독 실행 시” 어떻게 쓰이는지 등 세 부분으로 구성되어 있습니다.
데이터가 잘 들어오는지 실행
python scraper.py
🔖 최종 코드
import requests
from typing import List, Dict
class MusinsaAPI():
def __init__(self, keyword: str = "할인", page: int = 1, size: int = 60):
self.url = "https://api.musinsa.com/api2/dp/v1/plp/goods"
self.params = {
"gf": "A",
"keyword": keyword,
"sortCode": "POPULAR",
"page": page,
"size": size,
"caller": "SEARCH",
}
self.headers = {
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/138.0.0.0 Safari/537.36"
),
"Accept": "application/json, text/plain, */*",
}
def fetch(self) -> List[Dict]:
response = requests.get(self.url, params=self.params, headers=self.headers)
response.raise_for_status()
data = response.json()
goods_list = data.get("data", {}).get("list", [])
if not goods_list:
return []
result: List[Dict] = []
for g in goods_list:
result.append({
"goodsNo": g.get("goodsNo"),
"name": g.get("goodsName", ""),
"brand": g.get("brandName", ""),
"normalPrice": f"{g.get('normalPrice', 0)}원",
"saleprice": f"{g.get('price', 0)}원",
"linkUrl": "https://api.musinsa.com/" + g.get("goodsLinkUrl", ""),
"imageUrl": g.get("imageUrl", ""),
})
return result
# 실행 예시
if __name__ == "__main__":
api = MusinsaAPI(keyword="신발", size=5)
items = api.fetch()
print(items)
for idx, item in enumerate(items, start=1):
print(f"{idx}. {item['name']} - {item['saleprice']} ({item['linkUrl']})")
# 확장용 코드 예시
# keywords = ["신발", "가방", "스커트"]
# for kw in keywords:
# api = MusinsaAPI(keyword=kw, size=5)
# items = api.fetch()
# ...