
로딩 중이에요... 🐣
5. 쿼리하기 | ✅ 저자: 이유정(박사)
쿼리문들 (get(), create(), filter(), exclude(), save() 등)은 모델을 다루는 로직입니다. 목적에 따라 어떤 파일에 작성하는지 달라집니다.
Django 프로젝트에서 "쿼리(Query) = 데이터를 조회하거나 조작하는 동작"이 발생하는 위치들:
views.py: 클라이언트 요청에 따라 데이터를 가져오고 가공할 때(사용자가 검색한 책 목록, 책 등록 등)forms.py: 입력 값 검증 후, 객체 생성 또는 수정(form.save() 이전에 조건을 걸고 저장)admin.py: 관리자 페이지에서 목록 필터링, 자동 저장(save_model, get_queryset 등)tests.py: 테스트 데이터를 만들고 비교할 때(Book.objects.create(...) 등)management command (ex: commands/): 배치 작업, 데이터 초기화 등 스크립트성 로직(python manage.py myscript)Django shell(manage.py shell): 수동 테스트나 디버깅(Book.objects.get(...), save())
| 위치 | 쿼리의 목적 | 예시 | 특징 |
|---|---|---|---|
views.py |
클라이언트 요청 처리 | 사용자 검색, 글 조회 | 실시간 요청/응답용 |
forms.py |
입력값 검증 → 저장 전 조건 검사 | form.is_valid(), form.save() |
저장 전 데이터 필터링 |
admin.py |
관리자 화면 필터링, 저장 커스터마이징 | get_queryset(), save_model() |
관리자만 사용하는 쿼리 |
tests.py |
테스트 시 데이터 생성·비교 | Book.objects.create(), assertEqual() |
자동화된 검증 목적 |
management commands |
배치 처리 / 데이터 일괄 작업 | 사용자 초기화, 오래된 글 삭제 등 | 터미널 실행, 주기적 작업 |
shell (manage.py shell) |
직접 실험 및 디버깅 | Model.objects.all(), save() |
수동 실행용, 실시간 확인 |
Django의 ORM(Object-Relational Mapping) 기능 중에서 QuerySet API를 설명하는 예시로, 파이썬 코드로 데이터베이스에서 원하는 데이터를 조회, 생성, 수정, 삭제하는 방법입니다. 이것은 SQL을 직접 작성하지 않아도 되도록 도와주는 Django ORM의 문법입니다.
위치: 보통 views.py 또는 Django Shell
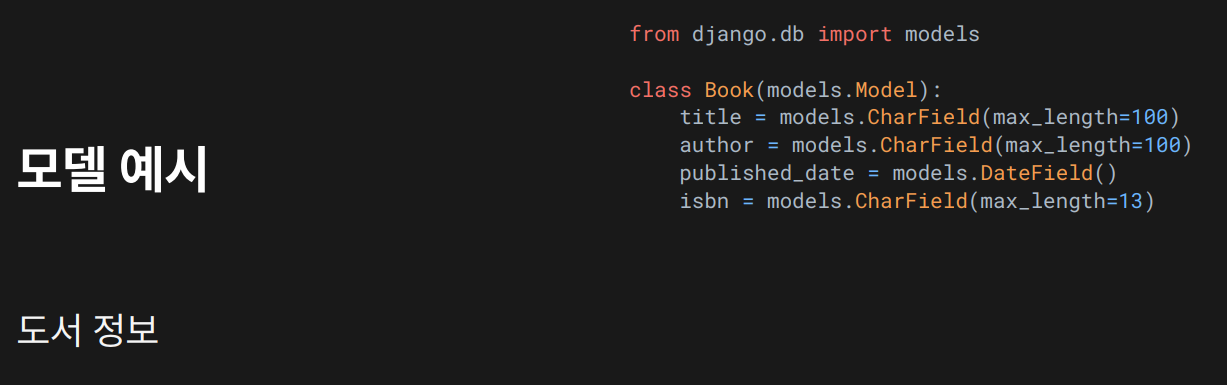
단일 객체 가져오기
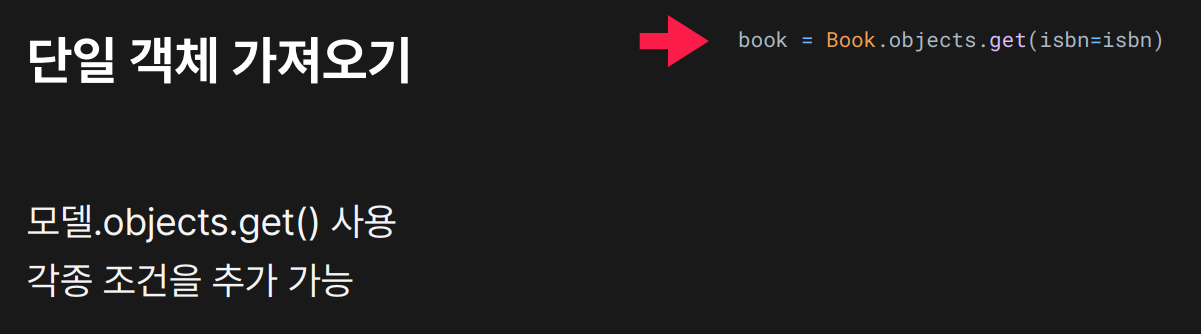
- 조건을 만족하는 하나의
Book객체만 가져옴. - 없으면
DoesNotExist에러 발생.
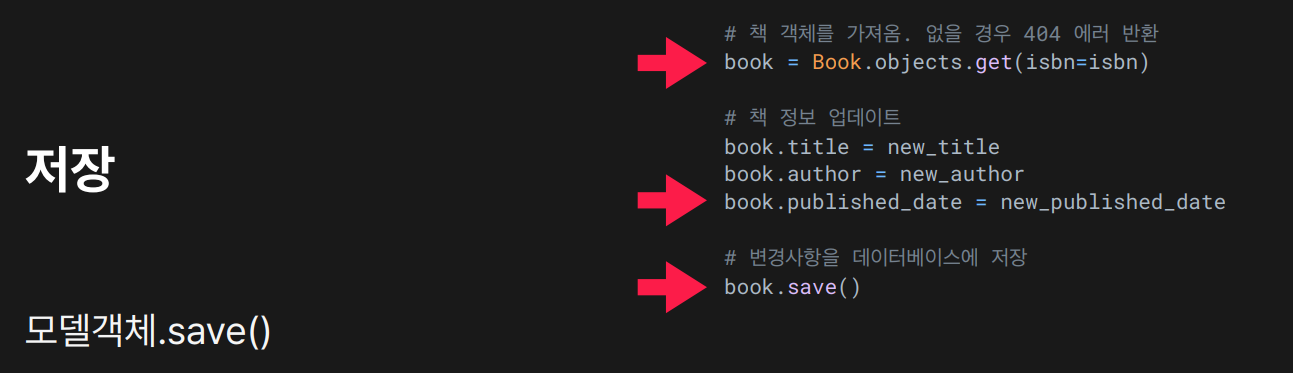 필드를 바꾼 후
필드를 바꾼 후 .save() 하면 변경사항이 DB에 반영됨.
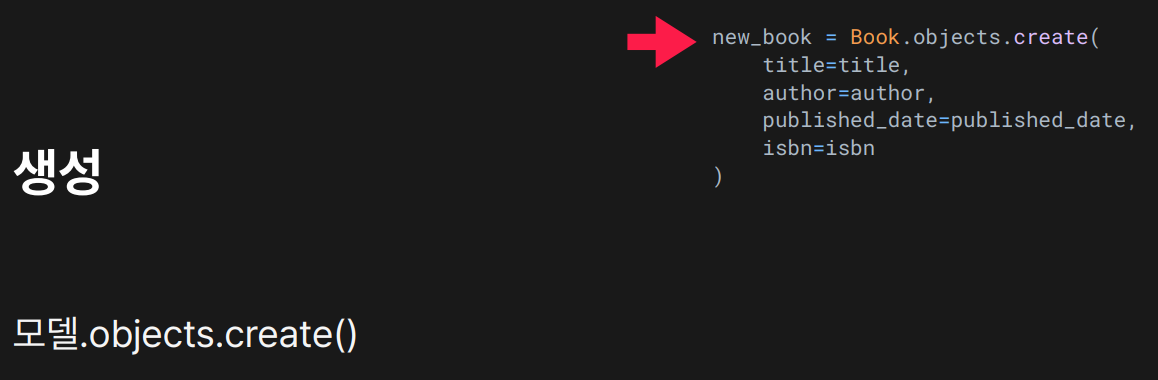 새로운 객체를 생성
새로운 객체를 생성
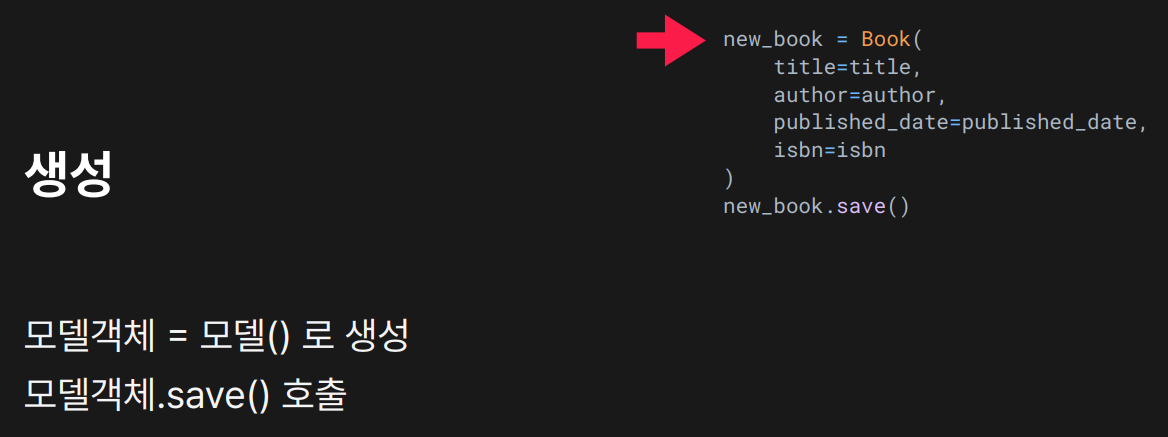 생성한 객체를 DB에 저장함.
생성한 객체를 DB에 저장함.
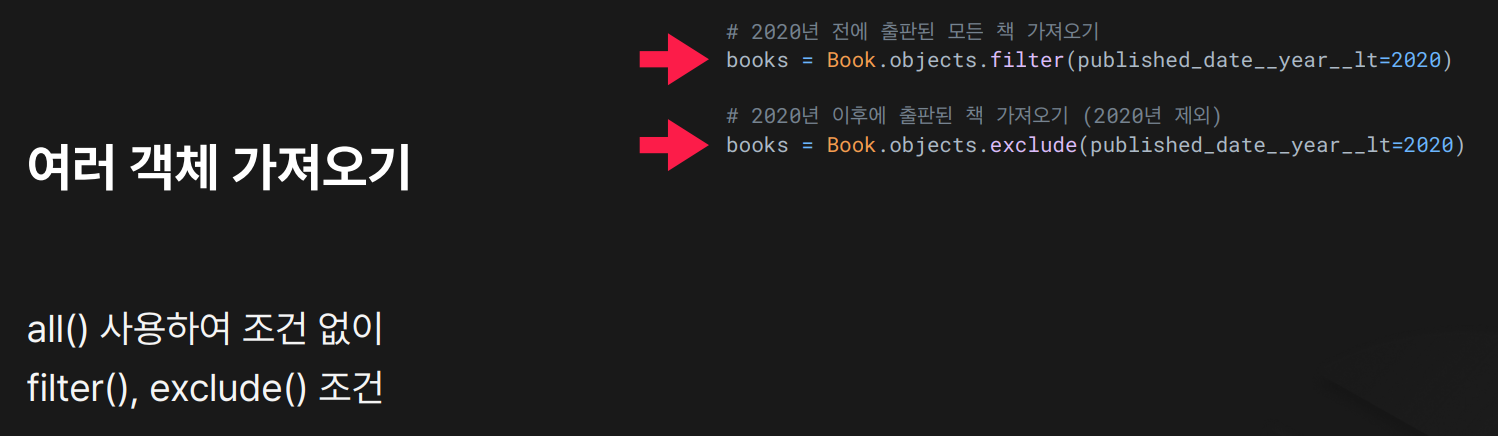
위치: 보통 views.py, QuerySet 로직 : 여러 개의 객체 가져오기
Lookup이란?
Lookup은 Django의 ORM 쿼리에서 .filter(), .exclude(), .get() 등에 쓰이는 조건 연산자입니다. SQL의 WHERE 조건처럼 동작하죠.
이 표현식들은 어디에서 사용될까?
views.py : 사용자가 요청한 조건에 맞는 데이터를 조회할 때
forms.py : 유효성 검사 후 조건에 맞는 데이터를 찾을 때
tests.py : 테스트 데이터를 조건에 따라 필터링할 때
management command : 자동 스크립트나 배치 처리 중 특정 조건 검색
shell : 디버깅, 수동 쿼리 시 직접 조회
목적: 해당 필드가 NULL인지 확인할 때
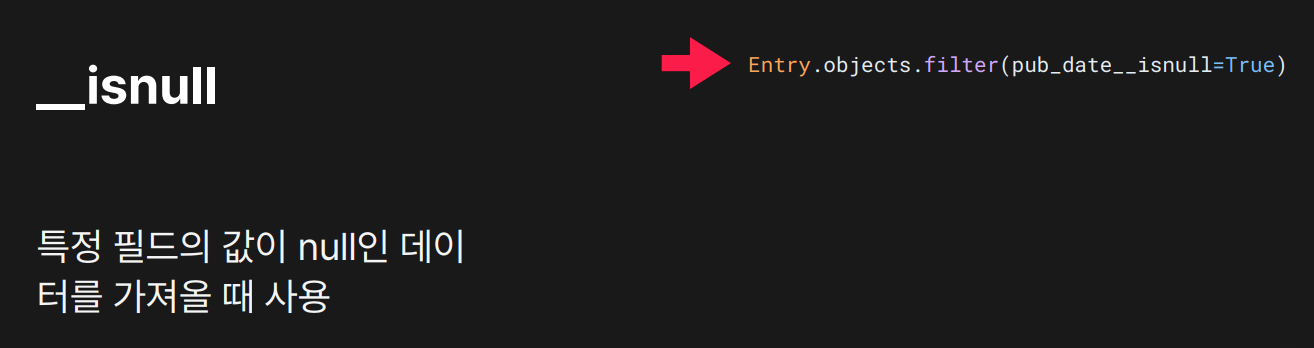 결과:
결과: pub_date 필드가 비어 있는(=null인) 데이터를 가져옴.
목적: 특정 필드 값이 주어진 값들 중 하나일 때
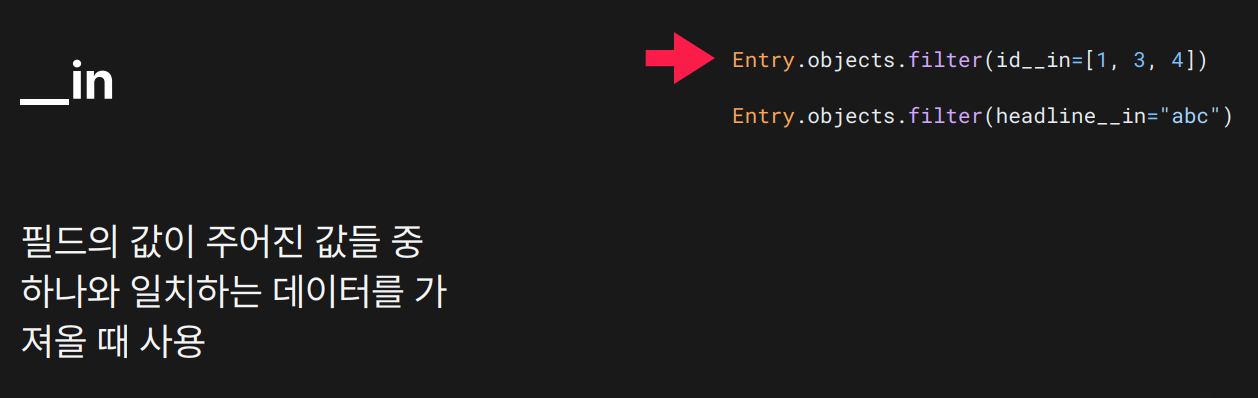 결과: id가 1, 3, 4 중 하나인 객체들을 가져옴
결과: id가 1, 3, 4 중 하나인 객체들을 가져옴
목적: 필드의 값이 주어진 값보다 "큰" 경우
 결과: id가 5 이상인 데이터만 가져옵니다.
결과: id가 5 이상인 데이터만 가져옵니다.
목적: 필드의 값이 주어진 값보다 "크거나 같은" 경우
 결과: id가 4 이상인 데이터.
결과: id가 4 이상인 데이터.
목적: 지정된 값보다 작은 값을 가진 데이터를 조회할 때 사용합니다.
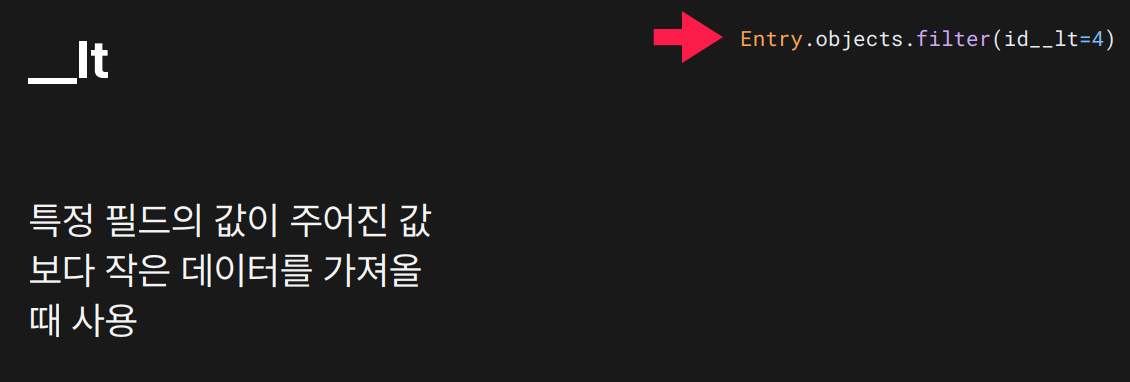 결과:
결과:id가 4보다 작은 Entry 객체들을 반환합니다.
목적: 지정된 값보다 작거나 같은 값을 가진 데이터를 조회할 때 사용합니다.
 결과:
결과: id가 4 이하인 Entry 객체들을 반환합니다.
목적: 문자열 필드에서 지정된 문자열이 포함된 데이터를 찾을 때 사용합니다.
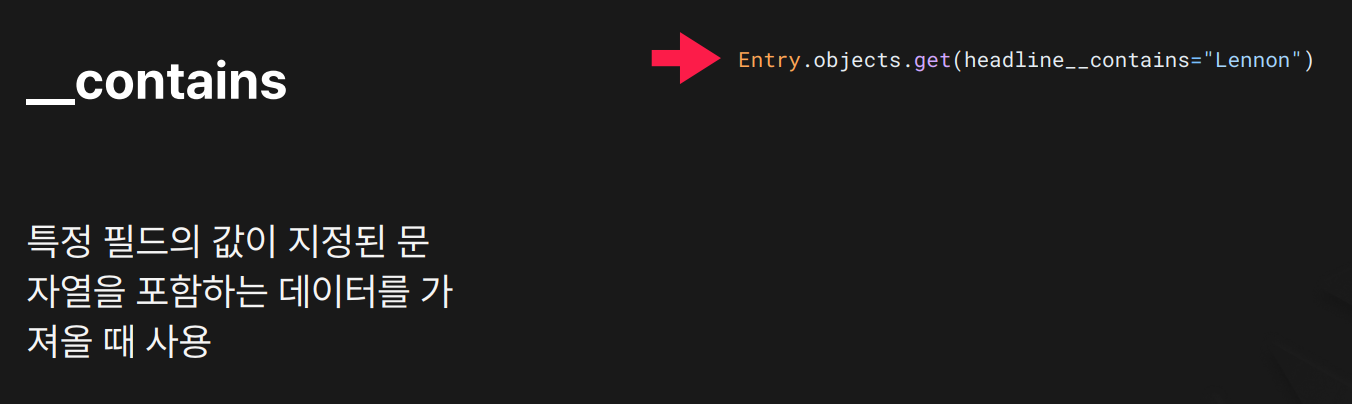 결과:
결과: headline 필드에 "Lennon"이라는 단어가 포함된 하나의 Entry 객체를 가져옵니다.
단, .get()은 여러 개가 검색되면 MultipleObjectsReturned 오류가 나고,
없으면 DoesNotExist 오류가 발생하므로 .filter()가 더 안전합니다.
목적: 지정된 문자열을 포함하는 데이터를 대소문자 구분 없이 검색할 때 사용합니다.
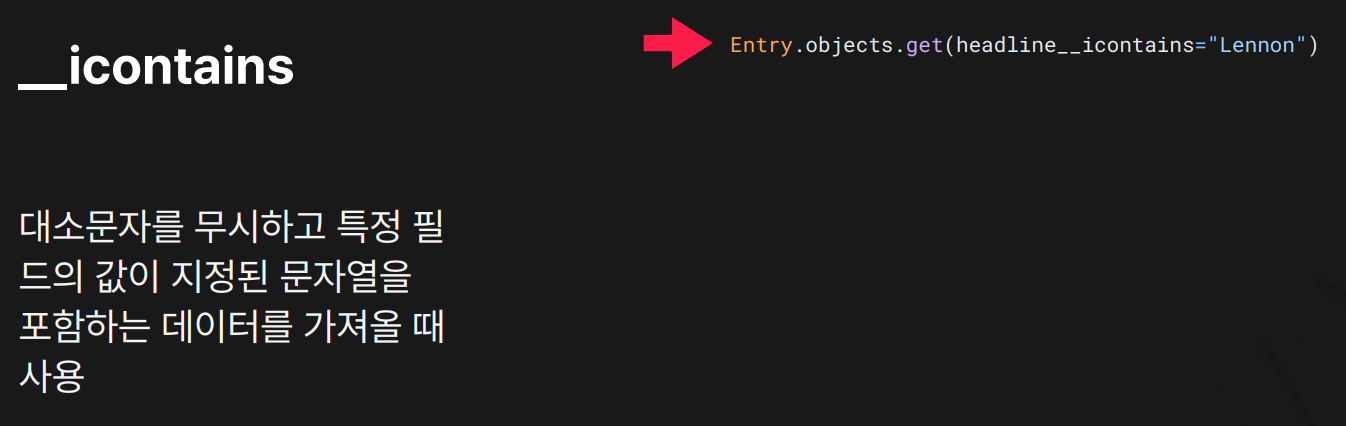 결과:
결과: headline 필드에 "lennon", "LENNON", "LeNnOn" 등 포함된 데이터를 모두 찾습니다.
SQL: WHERE headline ILIKE '%lennon%' (PostgreSQL 기준)
목적: 지정된 문자열로 시작하는 데이터를 대소문자 구분하여 검색할 때 사용합니다.
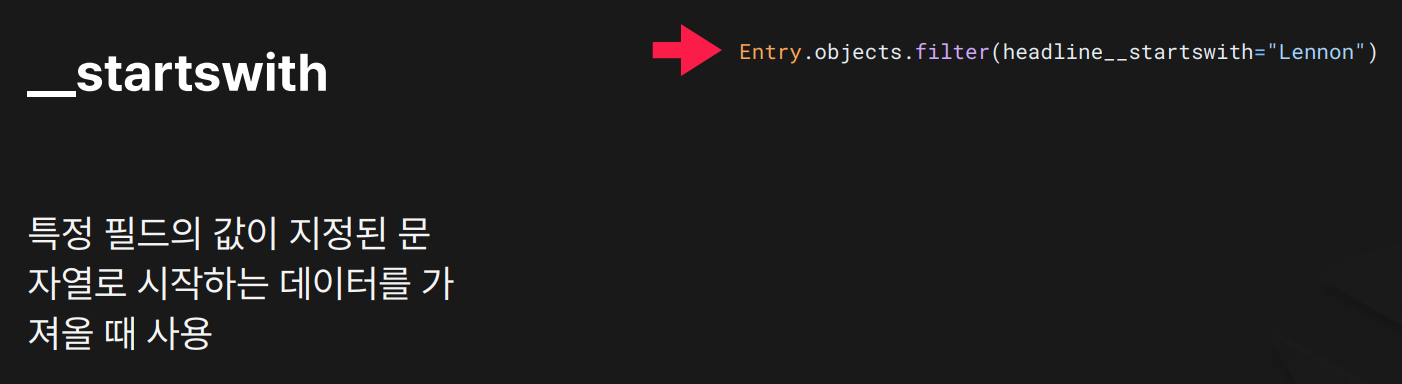 결과:
결과: headline이 정확히 "Lennon"으로 시작하는 데이터만 검색
"lennon"이나 "LENNON"으로 시작하는 값은 제외됨
목적: 지정된 문자열로 시작하는 데이터를 대소문자 구분 없이 검색할 때 사용합니다.
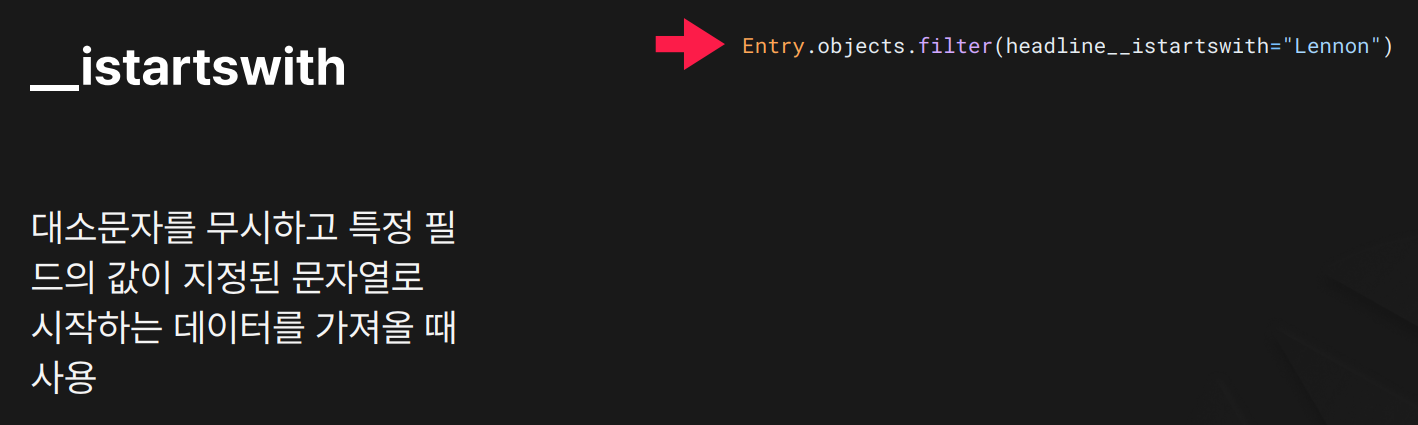 결과:
결과: "Lennon", "lennon", "LENNON" 등으로 시작하는 모든 값 포함
목적: 지정된 문자열로 끝나는 데이터를 필터링할 때 사용합니다. (대소문자 구분)
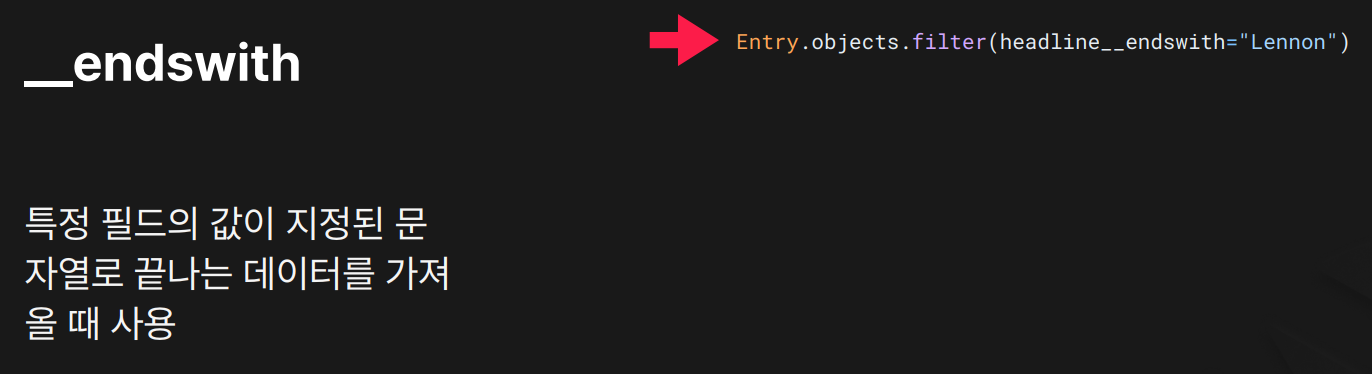 결과:
결과: headline이 정확히 "Lennon"으로 끝나는 데이터만 검색
목적: 지정된 문자열로 끝나는 데이터를 대소문자 구분 없이 필터링할 때 사용합니다.
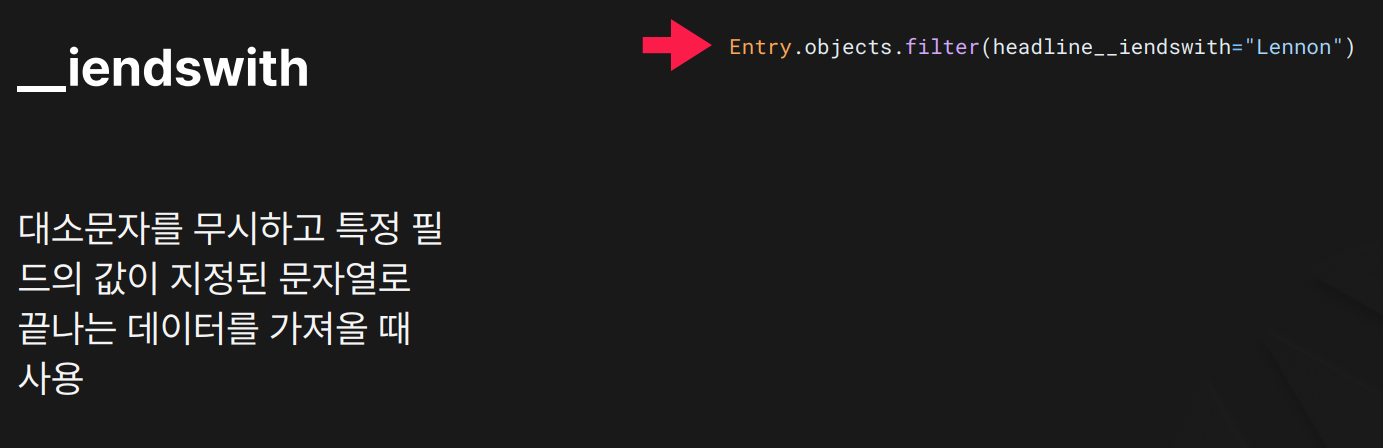 결과:
결과:"Lennon", "lennon", "LENNON" 등으로 끝나는 모든 데이터 검색
목적: 날짜, 숫자 등의 필드가 특정 범위에 속하는 데이터를 가져올 때 사용합니다.
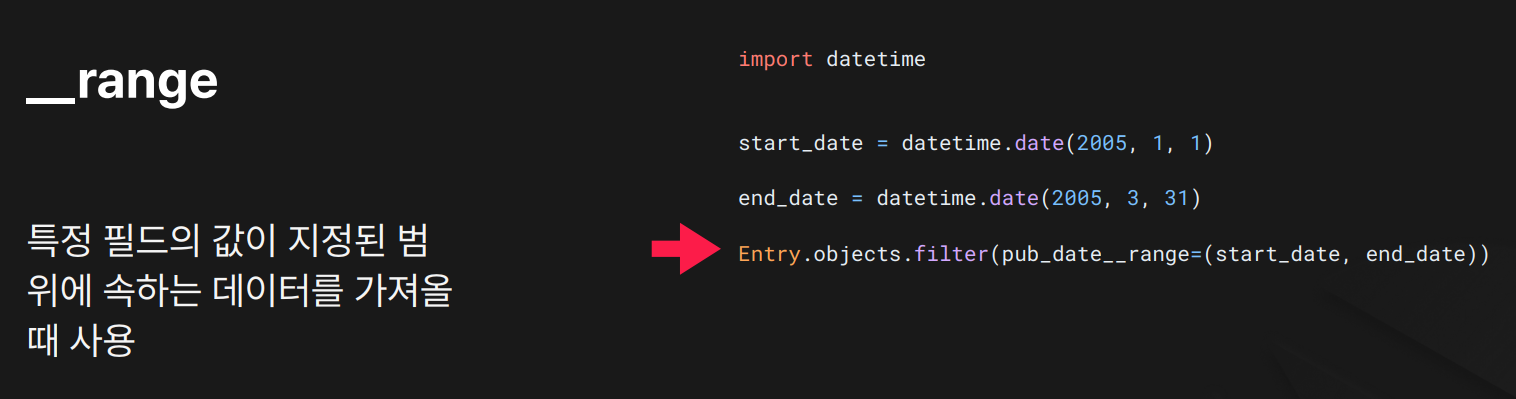 결과:
결과: pub_date가 2005년 1월 1일부터 3월 31일 사이인 데이터를 검색
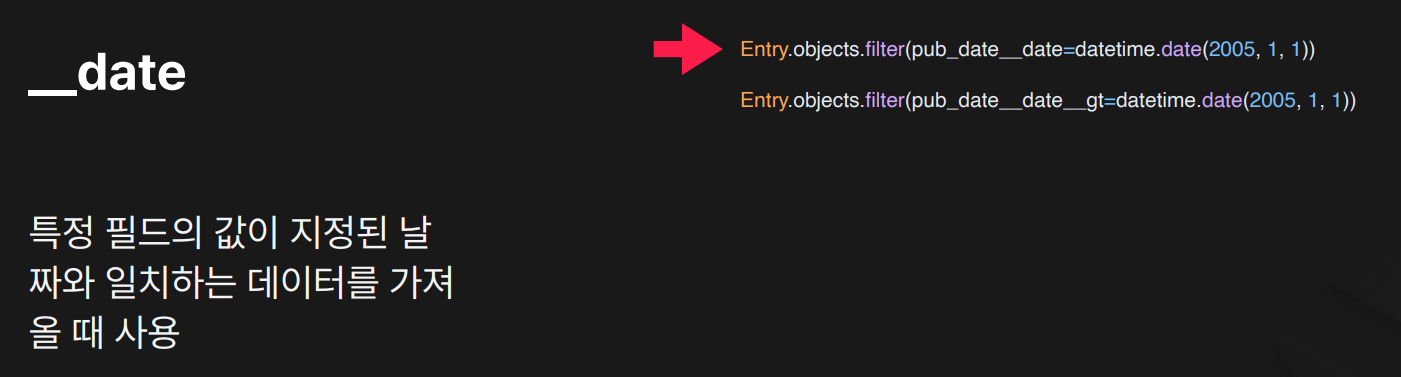
목적:날짜 필드(DateField, DateTimeField)에서 연/월/일 단위의 특정 날짜와 일치하는 값을 찾을 때 사용합니다.
 결과:
결과:
pub_date가 정확히"2005-01-01"인 데이터만 조회DateTimeField가2005-01-01 00:00:00~2005-01-01 23:59:59범위에 있어도 포함됨
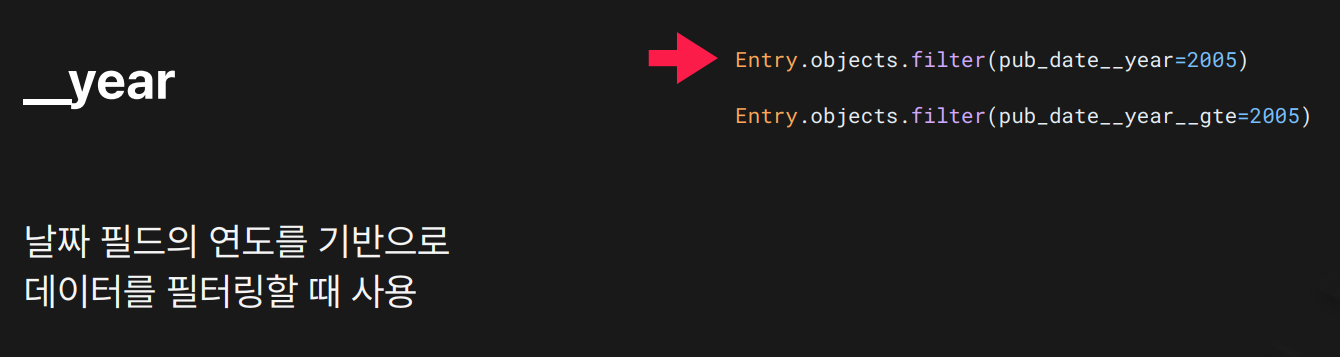
목적: 날짜 필드에서 연도(year) 기준으로 데이터를 필터링할 때 사용합니다.
 결과:
결과:
- 첫 번째 쿼리:
2005년에 해당하는 모든 데이터를 검색 - 두 번째 쿼리:
2005년 이상(2006, 2007...)의 데이터를 검색
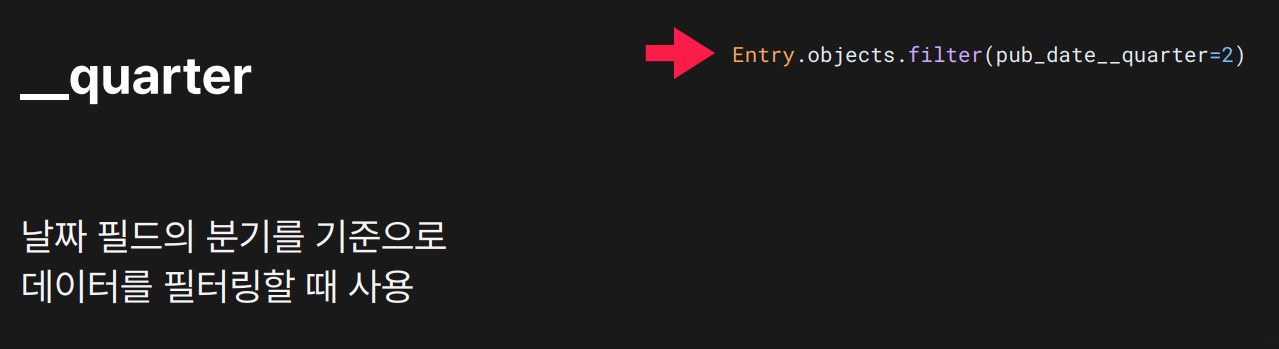
목적: 날짜 필드에서 분기(1~4분기) 기준으로 데이터를 필터링할 때 사용합니다.
 결과:
결과:
pub_date가 2분기(4월~6월) 에 해당하는 데이터 검색 분기 기준- 1분기: 1월~3월
- 2분기: 4월~6월
- 3분기: 7월~9월
- 4분기: 10월~12월
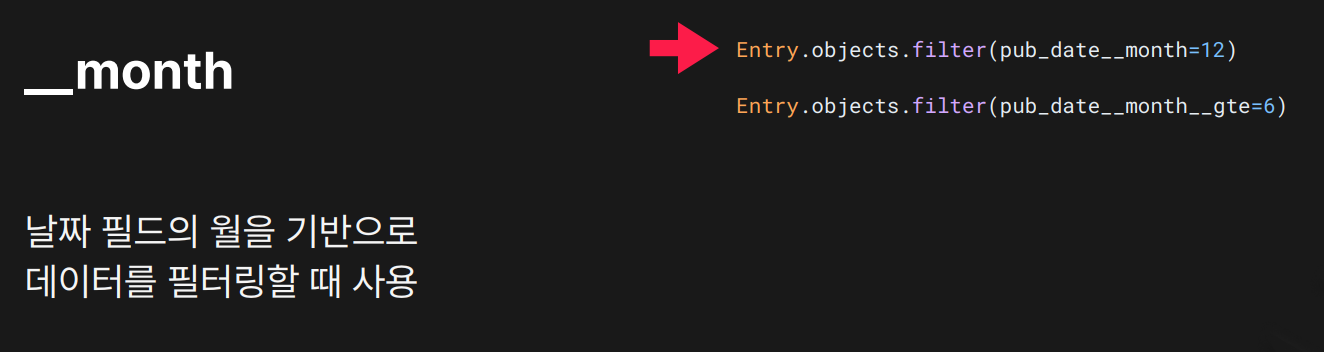
목적: 월(month) 기준 필터링
 결과:
결과: month=12이면 12월에 발행된 데이터 조회
목적: 일(day) 기준 필터링
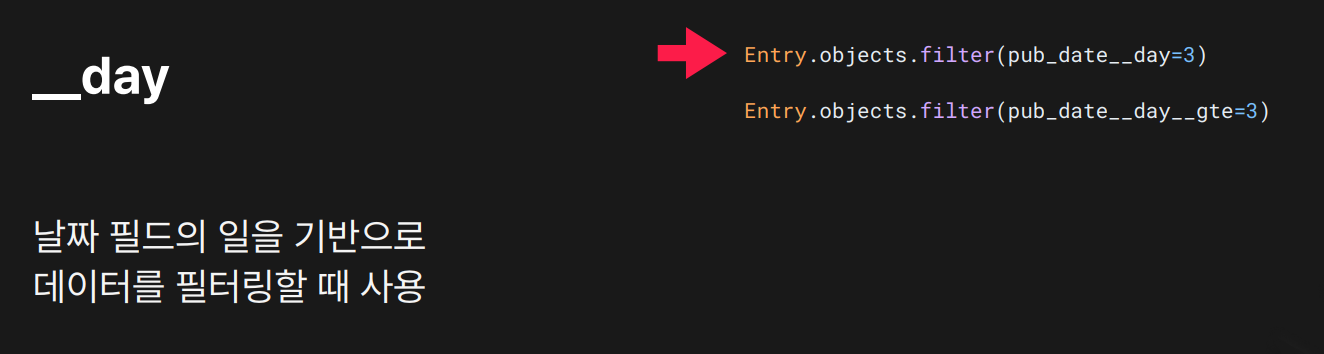 결과:
결과: day=3이면 3일에 발행된 데이터 조회
목적: ISO 기준 주(week) 기준 필터링
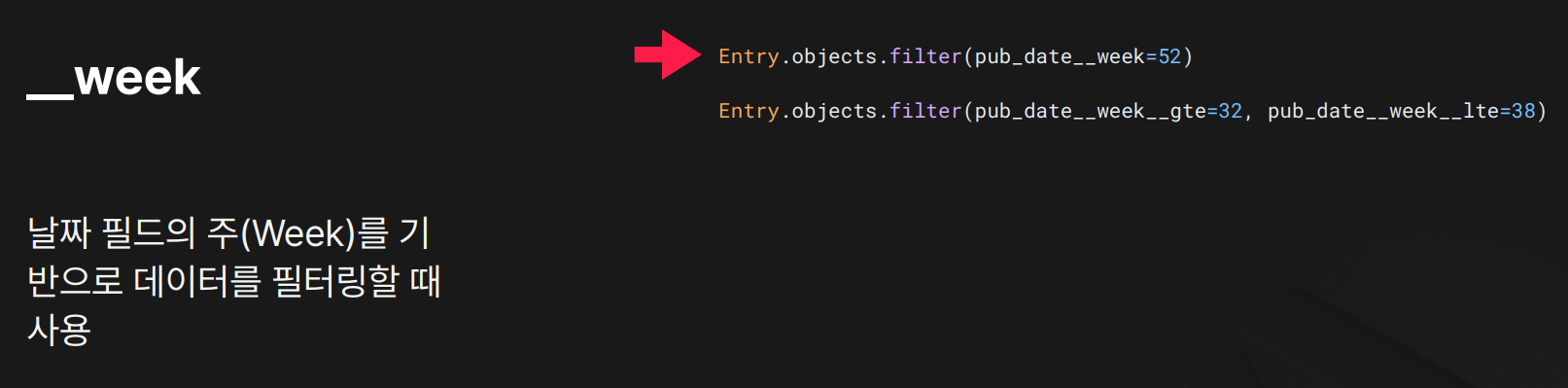 결과:
결과: week=52이면 1년 중 52주차 데이터
목적: 요일 기준 필터링 (1=일요일 ~ 7=토요일)
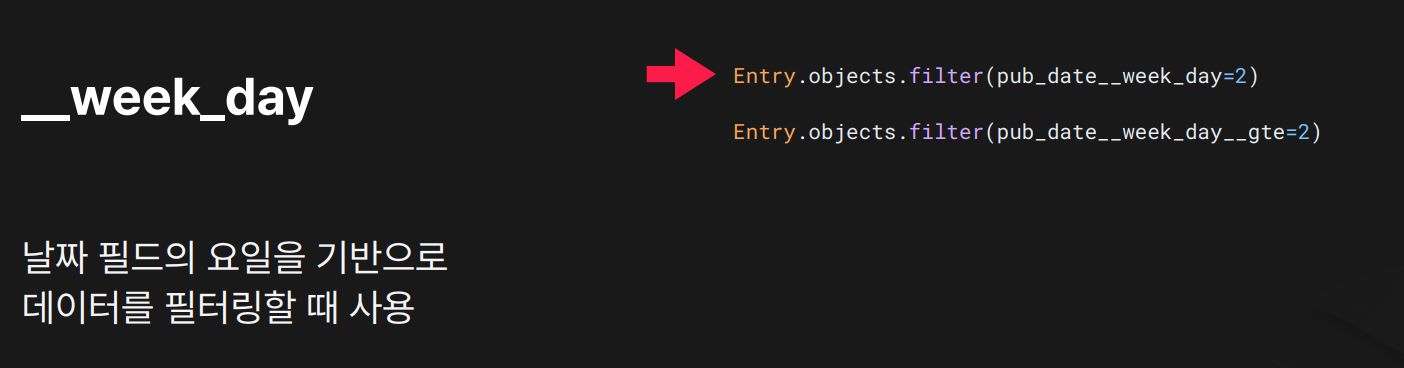 결과:
결과: week_day=2이면 월요일
목적: datetime.time() 기반 시각 기준 조회
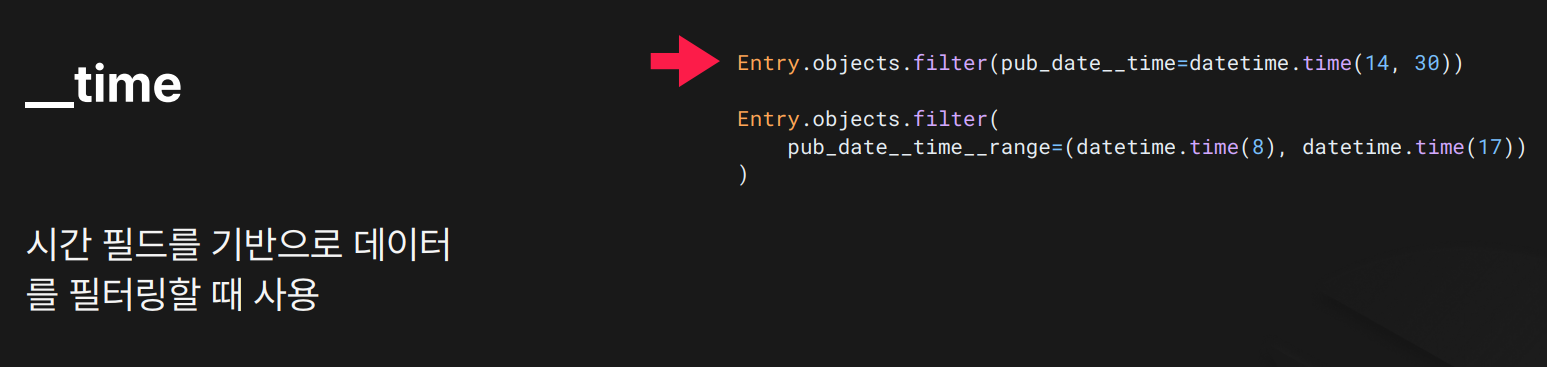 결과:
결과: time=(14,30) → 오후 2시 30분
목적: 시간 단위 기준 필터링
 결과:
결과: hour=23 → 오후 11시에 기록된 데이터
목적: 분 단위 기준 필터링
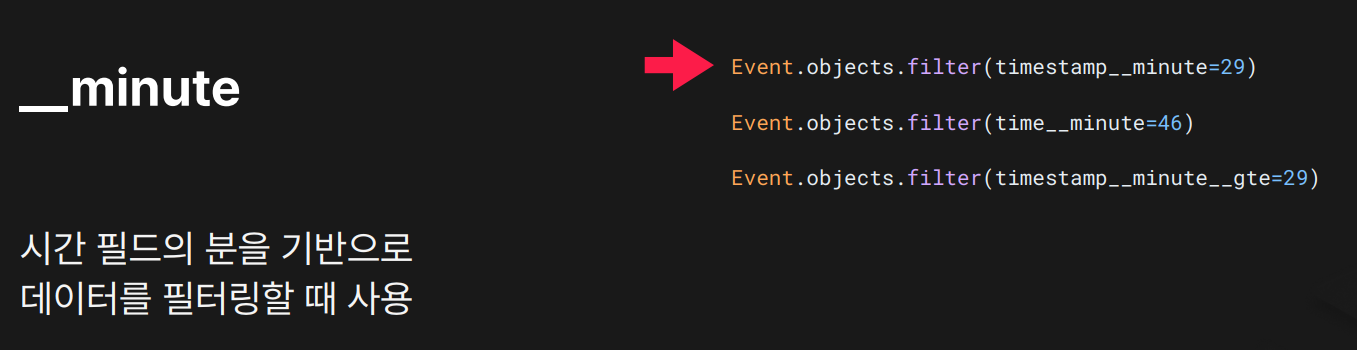 결과:
결과: minute=29 → 29분에 기록된 데이터
목적: 초 단위 기준 필터링
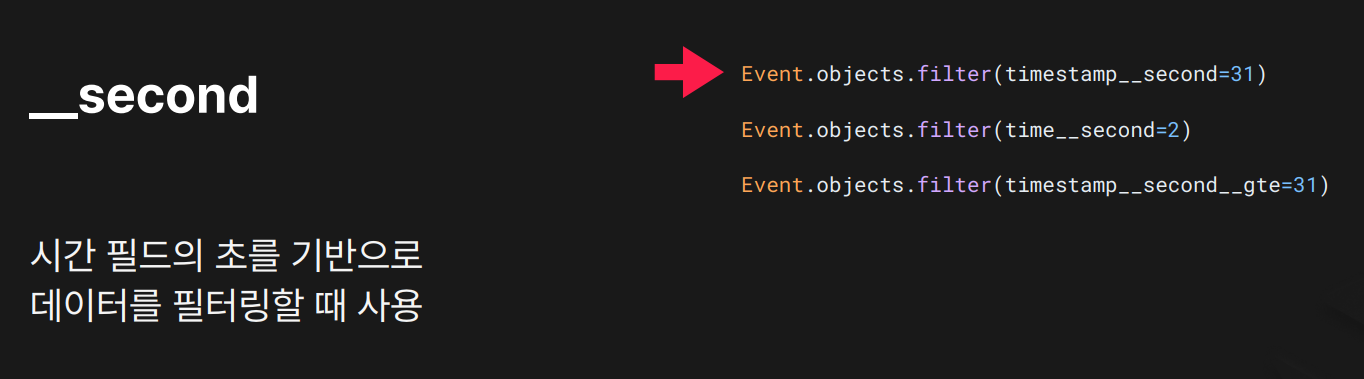 결과:
결과: second=31 → 31초에 기록된 데이터
목적: 대소문자 구분 O, 정규표현식 기반 필터링
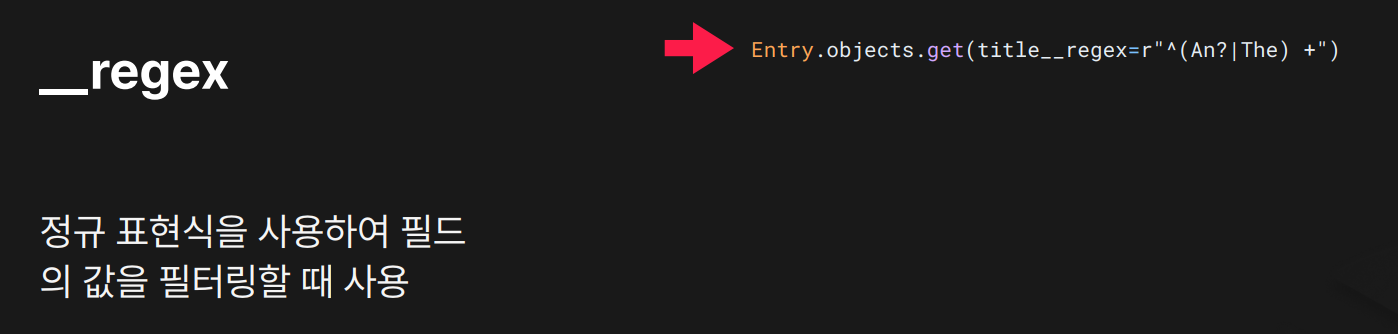 결과: `"^(An?
결과: `"^(An?
목적: 대소문자 구분 X, 정규표현식 기반 필터링
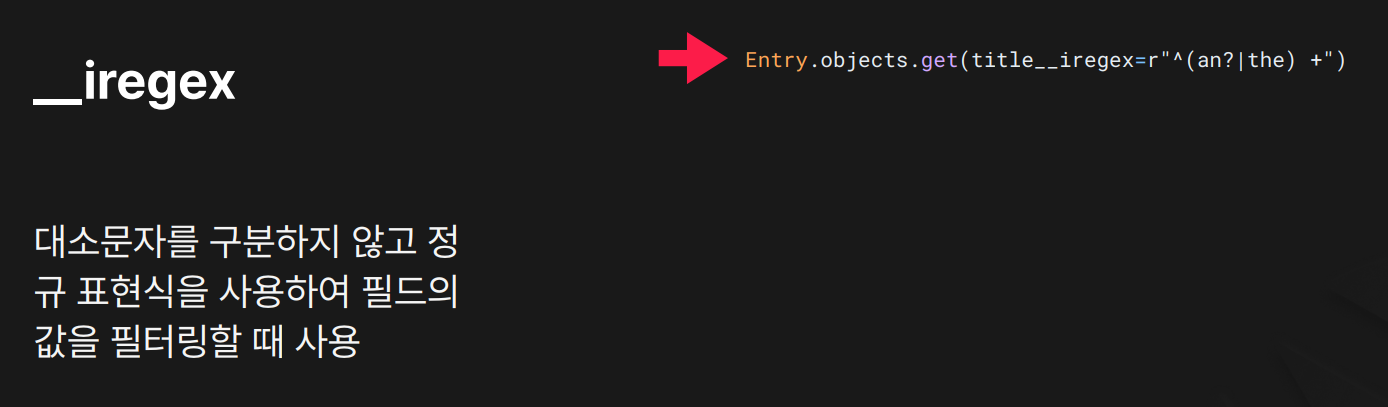 결과: 같은 정규표현식이지만 대소문자 무시됨
결과: 같은 정규표현식이지만 대소문자 무시됨
Django ORM의 Lookup 표현식이 관계 모델(ForeignKey) 에서 어떻게 활용되는지를 보여주는 예시:
"모델 간 관계를 따라가며 조회할 때도 __로 연결해서 Lookups을 사용할 수 있다!"
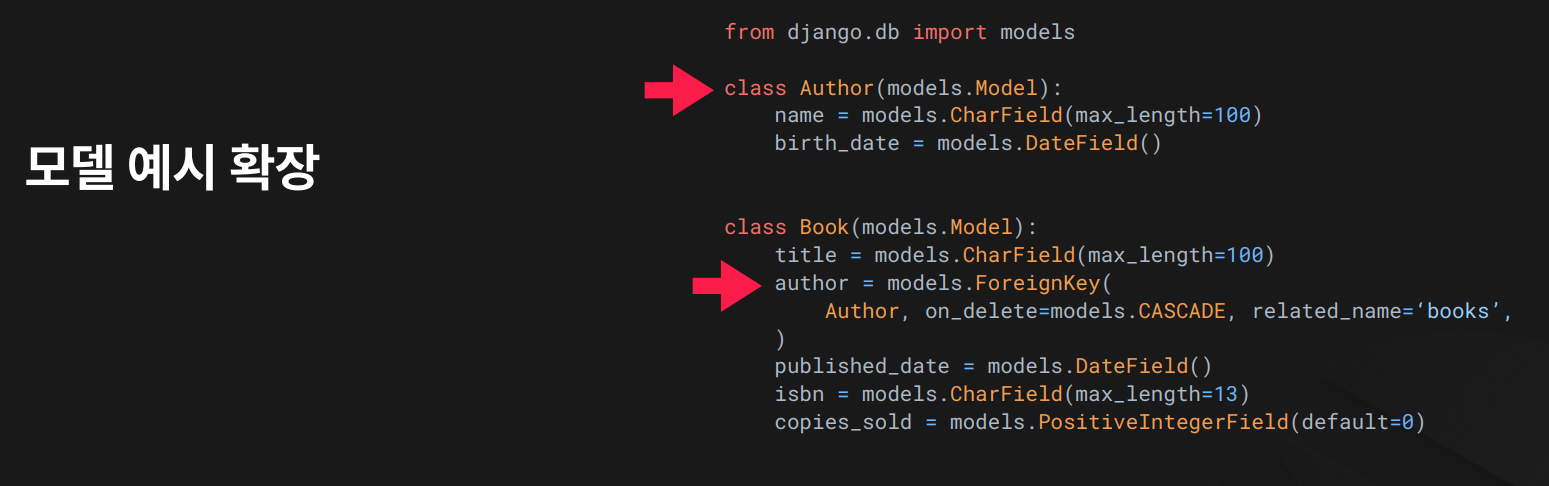
 관계 구조:
관계 구조:
Book은Author를 ForeignKey로 참조합니다.- 즉,
Book1권에는Author1명이 연결되어 있습니다 (1:N 관계). - 관계 필드 접근은
author__필드명식으로 접근합니다.
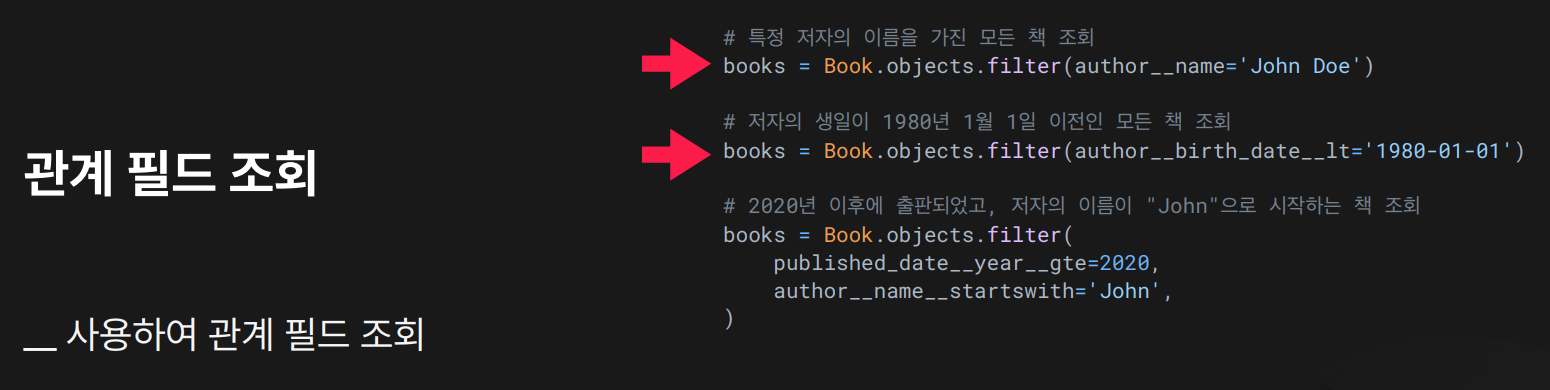
예시1:
books = Book.objects.filter(author__name='John Doe')
목적: 저자가 "John Doe"인 책들을 모두 조회 해석:
- Book → author (ForeignKey 관계 따라감)
- author → name 필드
- 조건: name이 정확히
'John Doe'
예제 2:
books = Book.objects.filter(author__birth_date__lt='1980-01-01')
목적: 저자의 생년월일이 1980년 1월 1일 이전인 책들 조회 해석:
- Book → author → birth_date
__lt(less than) 사용: 해당 날짜보다 과거
예제 3:
books = Book.objects.filter(
published_date__year__gte=2020,
author__name__startswith='John',
)
목적:
- 2020년 이후에 출판되었고
- 저자의 이름이
'John'으로 시작하는 책들 조회 해석: published_date__year__gte=2020: 출판일의 연도가 2020년 이상author__name__startswith='John': 저자 이름이'John'으로 시작
목적: .filter(), .exclude() 등 쿼리셋 메서드를 여러 번 연속해서 호출하여,
동적인 조건 조합을 통해 유연한 데이터 필터링을 하기 위함
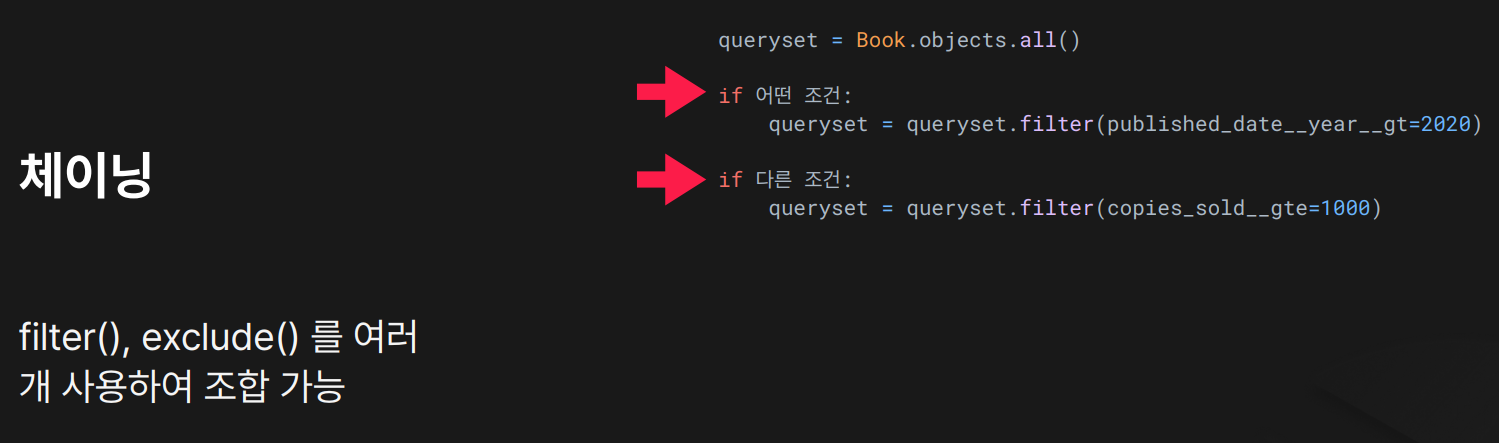 결과:
결과:
- 조건에 따라 동적으로
.filter()를 적용하여 2020년 이후 출판된 책이면서1000권 이상 판매된 책을 가져옴.filter()를 연달아 쓰면 AND 조건처럼 작동함
목적: order_by()를 사용하여 쿼리셋 결과를 원하는 순서로 정렬
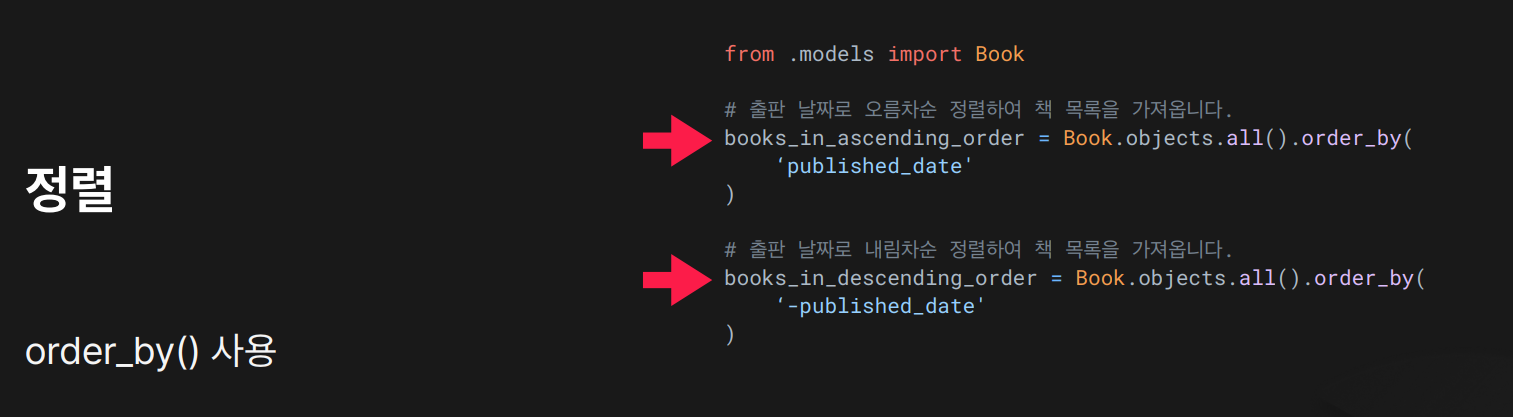 결과:
결과: published_date를 기준으로
오름차순('published_date'): 오래된 책이 먼저내림차순('-published_date'): 최근 책이 먼저 정렬되어 조회됨
목적: Q() 객체를 사용하여 OR 조건 등 복잡한 필터 조건을 구성할 수 있음.
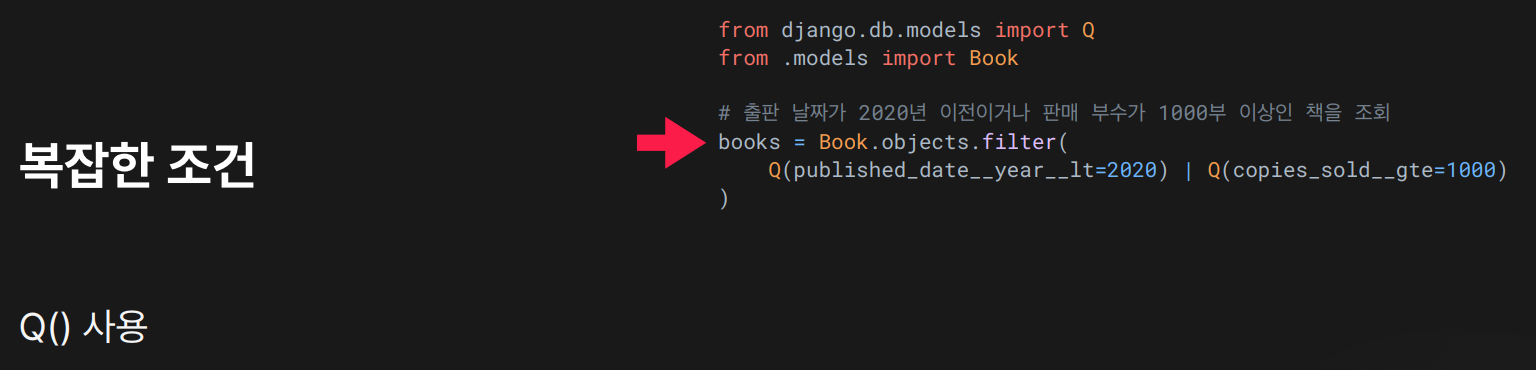 결과: 출판연도가 2020년 이전이거나, 판매 부수가 1000부 이상인 책들이 필터링되어
결과: 출판연도가 2020년 이전이거나, 판매 부수가 1000부 이상인 책들이 필터링되어 books에 저장됨.
목적: 특정 객체 또는 조건에 맞는 여러 객체를 삭제함.
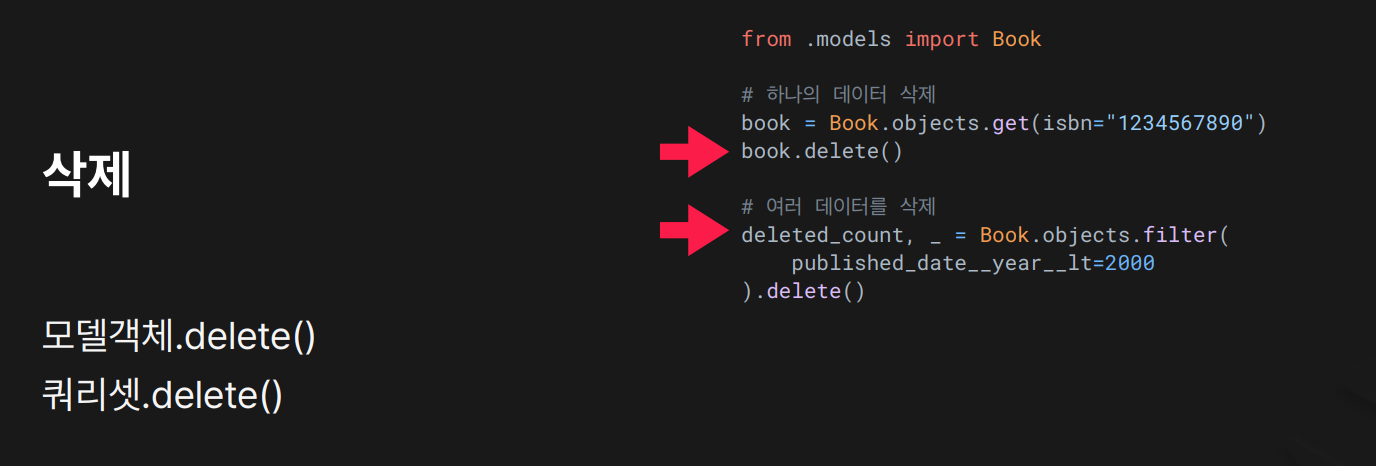 결과:
결과:
- 첫 번째 코드는
isbn이"1234567890"인 책 한 권을 삭제함. - 두 번째 코드는 2000년 이전에 출판된 모든 책을 삭제하고, 삭제된 객체 수가
deleted_count에 저장됨.
F 객체는 데이터베이스 필드 간의 연산을 가능하게 해주는 ORM 표현 객체입니다.
주로 update()나 filter()에서 현재 필드 값을 기준으로 연산하거나 비교할 때 사용합니다.
목적: update()를 사용하여 쿼리셋에 해당하는 모든 객체의 값을 일괄 수정함.
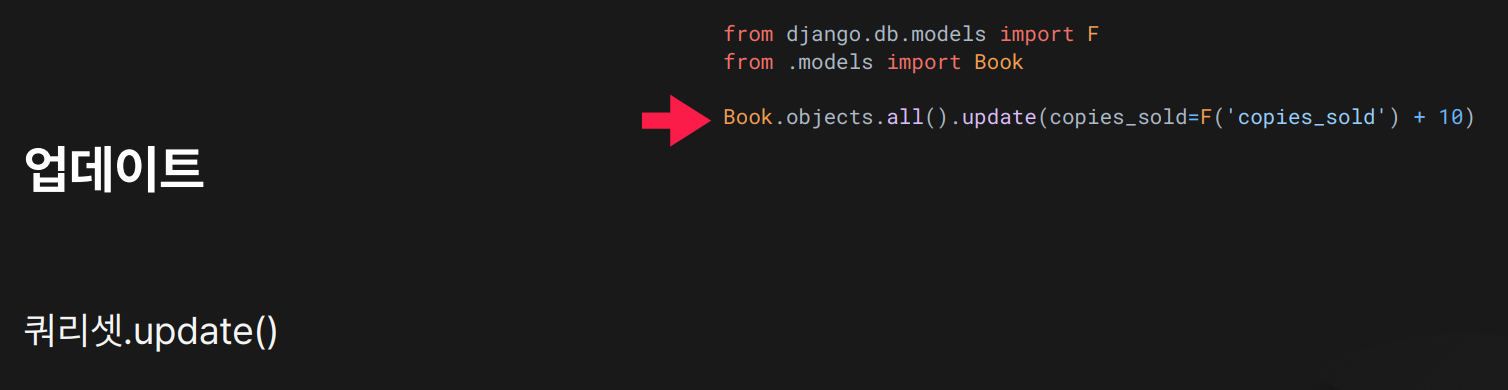 결과: 모든 책 객체의
결과: 모든 책 객체의 copies_sold 필드 값을 기존 값보다 10 증가시킴.
(예: 기존에 copies_sold=30이었다면, 업데이트 후 copies_sold=40)
목적: F() 객체를 사용하여 필드 값을 직접 참조하여 다른 연산에 활용함. (DB에서 값을 직접 읽어서 계산)
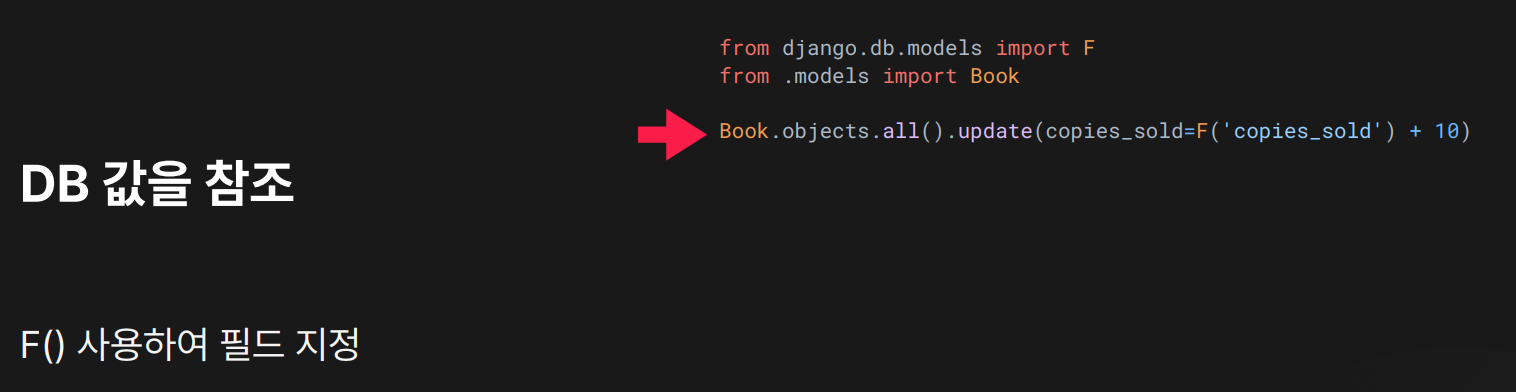 결과:
결과:
copies_sold필드의 기존 값을 DB에서 참조하여 10을 더한 값으로 업데이트함.- 중간에 다른 값으로 메모리에 로드하지 않고, SQL 레벨에서 바로 연산 수행.
파이썬 방식 vs F 객체 방식
- 일반적인 파이썬 방식 (비효율적)
book = Book.objects.get(id=1)
book.copies_sold = book.copies_sold + 10
book.save()
이 방식은:
book.copies_sold값을 파이썬 코드로 가져온 다음에- 메모리에서
+10연산하고 - 다시 DB에 저장(save) 하는 방식이에요. 이건 느리고, 동시 작업에서 꼬일 수 있어요.
F()객체 방식 (좋은 방식)
from django.db.models import F
Book.objects.filter(id=1).update(copies_sold=F('copies_sold') + 10)
이 방식은:
copies_sold필드의 값을 DB 안에서 바로 참조해서+10연산도 SQL에서 바로 계산하고- 바로 업데이트함
파이썬으로 가져오지 않아서 더 빠르고 안정적입니다.
F()는 필드 값을 가져오는 파이썬 변수가 아니라,
"DB 안의 컬럼 값을 직접 참조해서 계산하라"는 의미입니다. 속도도 빠르고, 데이터도 안전하게 처리돼요.